Durante meses my “sistema de logs” era SSH al servidor, docker logs nombre-del-container y rezar para encontrar el error antes de perder la paciencia. Cuando algo fallaba a las 3 de la mañana y me despertaba una alerta, el proceso era: conectarme, buscar en logs, no encontrar nada relevante porque el container había reiniciado y los logs anteriores habían desaparecido, rendirse.
Loki lo cambió. No es el sistema de logs más potente del mercado, pero para un homelab es perfecto: consume poco, se integra directamente con Grafana y funciona bien con Kubernetes desde el primer día.
Durante mucho tiempo ignoré los backups de mi cluster K3s. Tenía Proxmox Backup Server para las VMs, tenía el backup 3-2-1 para los datos importantes… pero el estado del propio cluster, los deployments, los ConfigMaps, los PersistentVolumeClaims: nada. Si el cluster petaba, tocaba reconstruir desde cero.
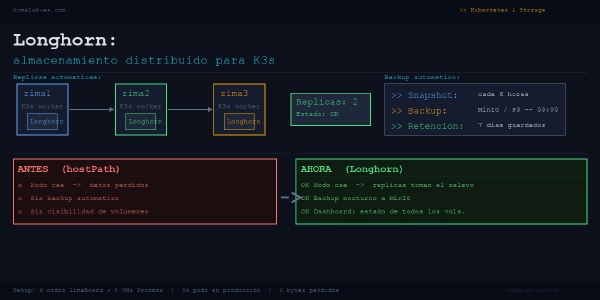
Llegó el momento en que un fallo de disco en uno de los nodos de Longhorn me dejó dos PVCs corruptos. No perdí datos críticos, pero me pasé un fin de semana reconfigurando servicios que debería haber tenido respaldados. Esa semana instalé Velero.
Después de perder datos por un nodo caído, instalé Longhorn en mi clúster K3s. Réplicas automáticas, backups a MinIO y snapshots integrados. Esto es lo que tendrías que saber antes de que te pase lo mismo.
Llevo tres años gestionando clusters Kubernetes. He aprendido kubectl, helm, kustomize, escribo YAMLs dormido, y aun así… hay días que abro Rancher y respiro tranquilo. Porque sí, kubectl es potente y la terminal mola. Pero cuando son las 3 de la mañana y algo se ha caído, ver gráficos de CPU en vez de piped JSON es la diferencia entre arreglarlo en 5 minutos o perder una hora.
Rancher no te convierte en peor administrador de Kubernetes. Te convierte en uno más eficiente. Y eso es lo que vamos a montar hoy.
Tengo una confesión: compro más libros de los que leo. Físicos, ebooks, audiolibros, lo que sea. El problema es que los tenía desperdigados por todas partes: Kindle, Audible, Google Play Books, archivos CBZ en carpetas random del NAS.
Hasta que monté Audiobookshelf y Kavita en el homelab. Ahora tengo una biblioteca digital centralizada, accesible desde cualquier dispositivo, con sincronización de progreso y sin depender de Amazon.
Te cuento cómo lo hice, qué aprendí, y por qué creo que es una de las mejores cosas que he montado en el homelab.
Tres ZimaBoard 2, una VPN mesh y ganas de sufrir. Así monté un clúster Kubernetes de producción que consume 20W y corre 34 pods. Tutorial paso a paso con todo lo que funcionó y lo que no.
He cometido el error dos veces ya. Montar algo “rapidito” en Docker Compose, que crece, se complica, y termino pasándolo a Kubernetes porque ya no puedo gestionarlo. Luego está el error contrario: montar un cluster K3s completo para hostear un solo contenedor que perfectamente podría vivir en un docker-compose.yml de tres líneas.
Después de gestionar ambos sistemas durante años en mi homelab (ahora mismo tengo varios equipos con Compose y un cluster K3s de tres nodos en ZimaBoard 2), creo que finalmente entiendo cuándo usar cada uno. Spoiler: no es solo “Compose para cosas simples, Kubernetes para lo complejo”. Es más sutil que eso.
Google Photos lleva años con mis recuerdos en sus servidores. Lo cambié por Immich corriendo en mi cluster K3s. Te cuento cómo lo monté, qué funciona, qué no, y por qué no volvería atrás.