El año pasado perdí un disco en mi servidor de almacenamiento. No fue un fallo catastrófico con chispas y humo, fue algo peor: el disco empezó a dar errores intermitentes durante semanas, los datos se corrompieron de forma silenciosa y me di cuenta tarde. Tardé tres días en recuperar todo desde el backup, y eso fue porque tenía backup. Muchos no lo tienen.
Desde entonces uso Scrutiny en todos mis servidores. Es un servicio Docker que recopila los datos S.M.A.R.T. de todos tus discos, los analiza y te manda una alerta cuando detecta valores que deberían preocuparte. No es infalible (los discos pueden fallar sin previo aviso S.M.A.R.T.) pero en mi experiencia la mayoría de fallos vienen precedidos de semanas o meses de señales que S.M.A.R.T. detecta si alguien está mirando.
Llevaba años oyendo que ZFS era la mejor decisión que podías tomar para el almacenamiento de tu homelab. Tardé demasiado en hacer el salto porque siempre me parecía que era demasiado complejo, que necesitaba hardware específico, que era “cosa de empresas”. Todo eso era mentira, pero entiendo por qué creí que era verdad.
La funcionalidad que me terminó de convencer fue los snapshots. Y este post es básicamente un argumento de por qué deberías conocerlos aunque ya tengas algún sistema de backup funcionando.
Durante mucho tiempo ignoré los backups de mi cluster K3s. Tenía Proxmox Backup Server para las VMs, tenía el backup 3-2-1 para los datos importantes… pero el estado del propio cluster, los deployments, los ConfigMaps, los PersistentVolumeClaims: nada. Si el cluster petaba, tocaba reconstruir desde cero.
Llegó el momento en que un fallo de disco en uno de los nodos de Longhorn me dejó dos PVCs corruptos. No perdí datos críticos, pero me pasé un fin de semana reconfigurando servicios que debería haber tenido respaldados. Esa semana instalé Velero.
Hay un problema que aparece tarde o temprano cuando llevas un tiempo con el homelab: necesitas almacenamiento de objetos compatible con S3. No porque seas Amazon, sino porque muchas herramientas modernas hablan S3 de forma nativa. Velero para backups de Kubernetes. Loki para logs. Restic, Rclone, Backblaze. Incluso algunas aplicaciones como Immich o Seafile pueden usar S3 como backend.
Si dependes de AWS S3 real, tienes un coste mensual variable y tus datos en manos de Amazon. MinIO resuelve eso: un servidor de objetos que habla la misma API que S3, que corres en tu propio hardware.
Perdí tres meses de trabajo una vez. No en un homelab, en un servidor de producción, pero la lección se me quedó grabada. Desde entonces tengo una regla no negociable: si no hay backup verificado, no existe.
Durante mucho tiempo usé las snapshots de Proxmox como backup. Es cómodo y rápido, pero es una trampa. Las snapshots viven en el mismo almacenamiento que las VMs. Si falla el disco, pierdes las VMs y las snapshots de golpe. Eso no es un backup, es una ilusión de seguridad.
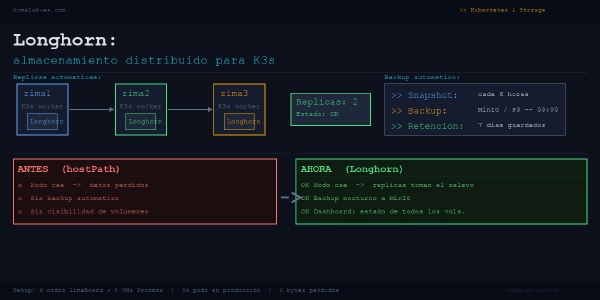
Después de perder datos por un nodo caído, instalé Longhorn en mi clúster K3s. Réplicas automáticas, backups a MinIO y snapshots integrados. Esto es lo que tendrías que saber antes de que te pase lo mismo.
Voy a empezar por el final: perdí datos. No una vez, dos veces.
Primera vez, 2022: un disco del NAS palmó. Pensaba que RAID 1 era backup. No lo es. Perdí 6 meses de fotos familiares porque el segundo disco falló 48 horas después del primero (RAID failure correlacionado, mismo lote de discos).
Segunda vez, 2024: actualización de Proxmox que se fue al carajo. Recreé las VMs desde cero, pero perdí configuraciones de servicios que no había documentado. 3 días de trabajo para volver a tener todo funcionando.