
Hay dos comandos de Proxmox que conviene no meter en el mismo saco: qm shutdown y qm stop.
Los dos acaban con una VM apagada si todo va como esperas. En la práctica no son la misma herramienta. Uno pide al sistema invitado que cierre limpio. El otro corta el proceso de QEMU de una forma mucho más brusca. Esa diferencia parece pequeña hasta que la máquina tiene una base de datos dentro, un filesystem ocupado, un servicio que tarda en parar o una tarea de HA vigilándola desde el cluster.
Yo antes era bastante más alegre con esto. Si una VM no respondía rápido, tiraba de botón fuerte y luego ya miraría. Mala costumbre. No siempre pasa nada, claro. Muchas veces el sistema arranca, el journal se recompone y la vida sigue. Pero cuando te toca la vez mala, la gracia dura poco. Un apagado a lo bruto puede dejarte un servicio con corrupción, un arranque lento, un disco pendiente de comprobar o una VM que vuelve a levantarse porque HA interpreta que se ha caído.
Ahora hago una lectura más aburrida y bastante más sana. Antes de apagar una VM desde terminal, miro estado, pienso qué hay dentro y elijo el comando según el daño que estoy dispuesto a aceptar.
la captura de este post#
La captura está basada en salidas reales de mi laboratorio, saneadas para quitar nombres internos. Me interesa enseñar lo que dice Proxmox, no publicar el inventario de casa.
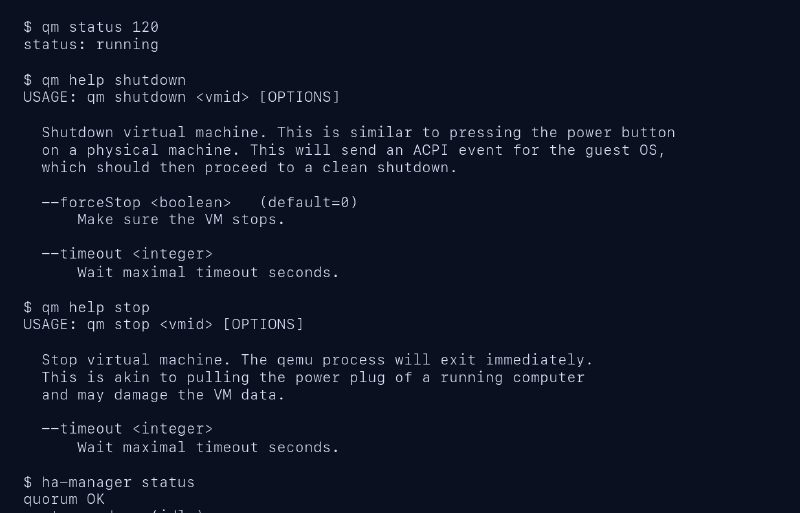
La propia ayuda de qm es bastante directa. qm shutdown se parece a pulsar el botón de encendido de un equipo físico. Envía una señal ACPI al sistema invitado y espera a que ese sistema se cierre. qm stop mata la VM de golpe. La ayuda lo compara con tirar del cable de corriente y avisa de que puede dañar datos.
Ese aviso no está ahí para decorar.
mi regla rápida#
Si la VM responde y no hay un incendio, uso qm shutdown.
Si la VM está colgada, el sistema invitado no responde, no hay forma razonable de entrar y el coste de esperar ya es peor que el riesgo de cortar, uso qm stop.
La frase parece obvia. Lo importante está en cumplirla cuando tienes prisa. El homelab tiene esa capacidad absurda de convertir un gesto de dos segundos en una tarde perdida. Vas a reiniciar una VM “un momento”, lo haces mal, y acabas mirando logs de arranque con cara de haber elegido violencia sin necesidad.
Por eso separo mucho estos dos comandos.
| |
Ese es mi primer intento normal.
| |
Ese lo trato como una intervención más agresiva.
antes de apagar, miro si de verdad está viva#
El primer comando no es ninguno de los dos. Es este.
| |
Quiero saber si la VM está running, stopped o en un estado intermedio. Parece una tontería, pero evita actuar sobre una idea vieja. La interfaz web puede estar abierta desde hace veinte minutos. Mi cabeza puede mezclar el estado de varias máquinas. La terminal no arregla todo, pero me da una lectura inmediata justo antes de tocar.
Si sale status: stopped, no hay apagado que hacer. Si sale running, ya pienso en el siguiente paso. Si veo algo raro, como una operación pendiente o una VM que no encaja con lo que esperaba, paro y miro tareas antes de forzar nada.
En un cluster, también miro HA si la VM está gestionada.
| |
No necesito leer una novela. Solo quiero saber si hay quorum, quién manda y si el LRM del nodo está sano. Si HA está activo para esa VM, cortar una máquina puede disparar decisiones automáticas. A veces es justo lo que quieres. Otras veces estás peleándote con el cluster sin darte cuenta.
qué hace qm shutdown#
qm shutdown pide al invitado que se apague. En una VM Linux moderna, eso normalmente entra por ACPI y termina en un apagado limpio gestionado por systemd. Los servicios reciben señal de parada, las bases de datos cierran, los buffers se vacían y el sistema desmonta lo que tenga que desmontar.
Cuando todo está bien, es el camino correcto.
La parte incómoda es que depende del invitado. Si el sistema está colgado, si ACPI no funciona bien, si systemd está esperando un servicio que no termina o si hay un proceso bloqueado en I/O, qm shutdown puede quedarse esperando. No significa que Proxmox esté roto. Significa que Proxmox ha pedido permiso y el invitado no está contestando como debería.
Por eso uso timeout.
| |
Tres minutos me parecen razonables para una VM normal. Para una base de datos pesada o una máquina con mucho I/O, puedo darle más. Para una VM pequeña de pruebas, a veces con 60 segundos llega. El punto es no dejarlo infinito ni cortar a los diez segundos por impaciencia.
También existe --forceStop.
| |
Esto intenta el apagado limpio y, si no lo consigue dentro del tiempo, fuerza la parada. Lo uso con cuidado. Me gusta porque expresa una intención ordenada: primero pido cerrar bien, luego acepto cortar si la máquina no coopera. Pero no lo lanzo sin pensar. Si dentro hay algo delicado, prefiero mirar por qué no apaga antes de permitir el golpe final.
qué hace qm stop#
qm stop corta el proceso de la VM. En términos prácticos, el invitado no tiene tiempo de cerrar con calma. Es como quitar corriente. Puede que no pase nada visible. Puede que el sistema recupere solo al arrancar. Puede que te deje una sorpresa.
Lo uso cuando la VM está realmente congelada o cuando necesito parar una máquina que ya no tiene un sistema invitado razonablemente vivo.
Ejemplos donde lo acepto:
- la VM no responde por red ni por consola
qm shutdownya agotó timeout- el QEMU guest agent no contesta
- el servicio está caído y la máquina no deja operar
- necesito liberar un bloqueo operativo y ya he revisado tareas recientes
Ejemplos donde intento no usarlo:
- una VM con PostgreSQL o MariaDB que todavía responde
- un servidor de ficheros con escrituras activas
- una máquina que forma parte de un cluster de aplicación
- cualquier cosa con backups o snapshots en curso
- una VM gestionada por HA sin mirar antes su estado
La diferencia es simple. Si hay vida dentro, intento hablar con ella. Si no hay vida, corto.
el guest agent cambia bastante la película#
Si la VM tiene QEMU Guest Agent instalado y funcionando, Proxmox puede saber más cosas del invitado. No convierte un apagado en magia, pero ayuda mucho. Para comprobarlo suelo lanzar:
| |
Si responde, tengo más confianza en que el invitado está accesible por la vía interna. En esos casos, antes de usar qm stop, suelo intentar apagar desde dentro o pedir un shutdown normal. Si no responde, no saco una conclusión automática, pero la señal pesa.
Muchas veces el guest agent falla por razones tontas. El servicio no está instalado. Está parado. La VM arrancó desde una plantilla vieja. El firewall interno no tiene nada que ver, porque el agente no va por la red normal, pero aun así hay instalaciones que lo dejan a medias.
Mi recomendación práctica: instala guest agent en todas las VMs que te importen. Luego activa agent: 1 en Proxmox. No por estética. Porque el día que tengas que apagar o diagnosticar, agradecerás esa línea.
ojo con los locks#
Proxmox usa locks para proteger operaciones. Si una VM está en backup, migración, snapshot o alguna tarea parecida, puede aparecer bloqueada. La tentación es tirar de --skiplock o qm unlock como si fueran una aspirina.
No lo hago de primeras.
Un lock puede estar ahí porque una tarea sigue viva. Saltártelo sin mirar puede dejar dos operaciones pisándose. Antes reviso tareas:
| |
O voy a la interfaz y miro la pestaña de tareas recientes. Si veo que el backup terminó hace media hora pero el lock quedó enganchado, entonces ya valoro limpiar. Si veo una tarea activa, espero o investigo. El lock no es el enemigo. Muchas veces es la única barrera entre tú y una liada mayor.
Con qm shutdown y qm stop pasa igual. Que exista --skiplock no significa que sea una opción normal. Es una herramienta para casos concretos, no un atajo.
cuando HA está de por medio#
La alta disponibilidad en Proxmox está muy bien, pero obliga a pensar un poco distinto. Si una VM está gestionada por HA, Proxmox intenta mantenerla en el estado deseado. Si tú la paras por fuera sin entender ese estado, puedes acabar con una VM que vuelve a arrancar o que se mueve a otro nodo.
Antes de apagar una VM con HA, miro:
| |
Si quiero mantenimiento real, prefiero poner el recurso en un estado claro desde HA antes de tocar la VM a lo bruto. Si solo quiero reiniciar el sistema invitado, entonces uso apagado limpio y compruebo que el cluster no interpreta la operación como fallo.
En homelab esto parece exagerado hasta que tienes tres nodos, almacenamiento compartido y un par de servicios que no quieres que desaparezcan. Ahí HA deja de ser una casilla bonita y pasa a ser una pieza que puede ayudarte o morderte.
mi secuencia normal#
Cuando necesito apagar una VM sin drama, hago algo parecido a esto:
| |
Si la VM queda parada, perfecto. Si sigue viva, miro consola, tareas y logs. Solo después decido si fuerzo.
| |
No es una liturgia. Es una forma de dejar rastro mental. Primero confirmo estado. Luego intento apagado limpio. Luego verifico. Si tengo que cortar, al menos sé por qué he llegado ahí.
casos reales donde me ha salvado ir despacio#
El caso más típico es la VM que parece colgada pero solo está tardando en parar un servicio pesado. Una vez me pasó con una máquina que estaba cerrando contenedores con volúmenes lentos. Desde fuera parecía muerta. Si hubiese lanzado qm stop a los treinta segundos, probablemente no habría pasado nada grave, pero tampoco hacía falta. A los dos minutos terminó sola.
Otro caso habitual es el invitado sin red. Si una VM no responde por SSH, mucha gente la da por rota. Pero puede estar perfectamente viva, solo sin conectividad. Ahí la consola de Proxmox o el guest agent te cambian la lectura. Si el sistema está bien y lo que falla es red, apagar a golpes no arregla la causa.
También está el caso contrario. VM viva por fuera, servicio roto por dentro. Ahí reiniciar la máquina entera puede ser una forma perezosa de esquivar el diagnóstico. A veces lo hago, no voy a fingir pureza. Pero si el patrón se repite, el problema no es qm shutdown. El problema es que estoy usando Proxmox como martillo para un fallo de aplicación.
lo que no hago ya#
Ya no uso qm stop como primer reflejo.
Ya no ignoro HA porque esto sea casa.
Ya no desbloqueo una VM sin mirar tareas.
Ya no doy por buena la foto mental que tenía de la VM hace un rato.
Y, sobre todo, ya no trato todas las VMs igual. No es lo mismo una máquina de pruebas que puedo recrear en diez minutos que una VM con servicios de familia, automatizaciones, monitorización o datos que luego me va a tocar restaurar.
cómo lo dejo documentado#
Cuando una VM necesita un apagado raro, dejo una nota. Puede ser en mi sistema de documentación, en el ticket interno o en una nota simple. Lo importante es registrar si he tenido que usar qm stop, si había locks, si HA intervino y si el siguiente arranque mostró errores.
Parece burocracia hasta que el problema vuelve. Entonces tener una línea que diga “esta VM no apagó limpio, se forzó tras timeout de 180 segundos” vale más que veinte minutos de memoria difusa.
En homelab tendemos a documentar instalaciones nuevas y olvidarnos de los incidentes pequeños. Justo esos incidentes pequeños son los que enseñan cómo se comporta tu infraestructura de verdad.
mi conclusión#
qm shutdown es mi camino normal. qm stop es mi corte de emergencia.
Los dos tienen sitio. El error es tratarlos como equivalentes porque ambos terminan en una VM apagada. Proxmox te da herramientas bastante directas, pero no puede decidir por ti cuánto te importa lo que hay dentro de la máquina.
Mi regla queda así: primero pregunto, luego espero un tiempo razonable, después verifico y solo al final corto. Es menos emocionante que tirar del cable virtual. También me ha dado bastantes menos sustos.