
qm disk rescan es uno de esos comandos que no usas todos los días, pero cuando lo necesitas te evita mirar el almacenamiento con cara de sospecha general.
La situación suele empezar de forma poco dramática. Una VM no enseña el disco que esperabas. Has movido algo de storage. Has restaurado una máquina. Has tocado una configuración desde terminal. O simplemente Proxmox parece no haber refrescado bien lo que hay en un backend. Abres la web, miras los discos, miras el storage, vuelves a mirar la VM y empiezas a pensar que algo no cuadra.
En ese momento prefiero no ponerme creativo. Primero quiero saber qué ve Proxmox en los storages y qué sería capaz de asociar o actualizar si le pido que haga un rescan.
La parte importante: casi siempre empiezo con --dryrun.
| |
No escribe cambios en las configuraciones de las VMs. Solo enseña por dónde iría la operación. Para mí eso cambia mucho el tono del diagnóstico. Puedo mirar sin alterar el estado del cluster. En almacenamiento, esa diferencia importa.
la captura de este post#
La salida viene de un nodo real de mi laboratorio y está saneada. He cambiado nombres de storage y he quitado detalles internos, pero he dejado el comportamiento interesante: el dry-run avisa de que no va a escribir y aun así tropieza con un local-lvm inactivo.
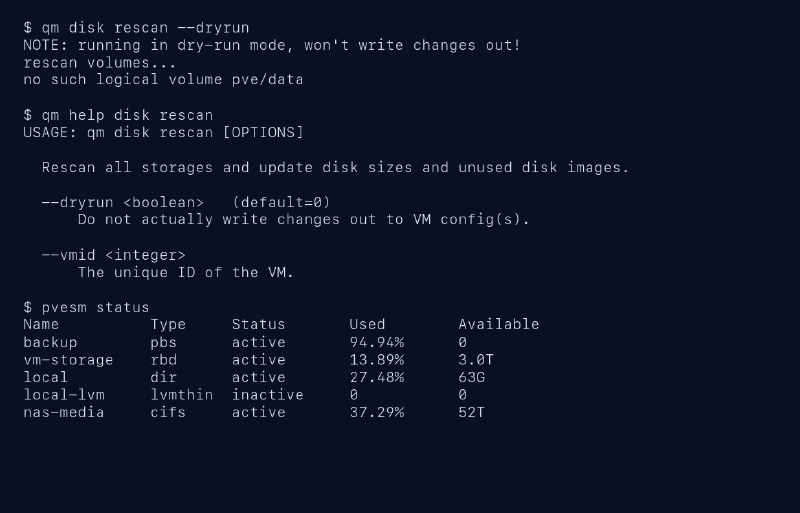
Ese detalle me gusta mucho porque enseña algo que las guías limpias suelen ocultar. Los comandos de diagnóstico no siempre devuelven una salida preciosa. A veces te muestran justo la pieza incómoda del entorno.
En este caso, pvesm status deja claro que hay un storage local-lvm inactivo. El rescan lo toca lo suficiente como para que aparezca el aviso no such logical volume pve/data. Eso no significa automáticamente que todas las VMs estén mal. Significa que antes de culpar a Ceph, a RBD, a CIFS o a una VM concreta, conviene revisar el inventario de storage.
qué hace realmente qm disk rescan#
La ayuda de Proxmox lo resume así: vuelve a escanear los storages y actualiza tamaños de disco e imágenes sin usar.
En cristiano, busca volúmenes que existen en el almacenamiento pero que quizá no están bien reflejados en la configuración de una VM, y también refresca tamaños cuando hay cambios que Proxmox no ha incorporado todavía.
Esto aparece mucho en varios escenarios bastante normales.
- restauraciones o movimientos que dejan discos como
unused - cambios de tamaño hechos fuera del flujo normal
- storages que estuvieron caídos o inactivos durante una operación
- migraciones o pruebas donde una VM cambia de backend
- limpieza posterior a incidencias
No es una herramienta para arreglarlo todo. Tampoco sustituye a entender dónde vive cada disco. Pero te da una forma relativamente ordenada de pedirle a Proxmox que vuelva a mirar.
por qué uso siempre --dryrun primero#
Porque el almacenamiento no se toca con fe.
El modo dry-run me permite ver si Proxmox detecta algo antes de escribir en configuraciones. Si el entorno está limpio y el comando no propone nada raro, ya tengo una señal. Si aparece un error, un storage inactivo o una ruta inesperada, puedo parar ahí.
| |
Solo cuando entiendo la salida me planteo ejecutar sin dry-run.
| |
No estoy diciendo que el comando sea peligroso por defecto. Proxmox sabe lo que hace. Lo que digo es que yo no necesito escribir cambios para orientarme. Y si puedo separar observación de acción, lo hago.
Esta costumbre me ha salvado de dos errores típicos. El primero, intentar arreglar una VM cuando el problema era un storage caído. El segundo, asumir que un disco sobrante era basura cuando en realidad pertenecía a una migración o a una restauración reciente.
empiezo por pvesm status#
Antes o después del rescan, miro almacenamiento.
| |
Quiero ver qué storages están activos, cuáles están inactivos y cuánto espacio real queda. En la captura saneada aparecen varios tipos: PBS para backups, RBD para discos de VM, directorio local, LVM thin y CIFS.
La columna que más miro al principio es Status.
Si un storage sale inactive, no sigo como si nada. Me pregunto si esa inactividad es esperada. A veces lo es. Por ejemplo, un local-lvm que ya no uso en ese nodo pero que sigue definido en la configuración del cluster. Otras veces es la pista principal del problema.
También miro el espacio disponible. Un storage de backups al 95 por ciento no explica todos los problemas, pero sí puede explicar comportamientos feos durante backups, retenciones y tareas de mantenimiento. Un RBD con espacio sano me da otra lectura. Un CIFS activo pero lento me lleva por otro camino.
Sin esa foto, qm disk rescan queda suelto.
limitar el rescan a una VM#
Cuando estoy investigando una máquina concreta, prefiero acotar.
| |
Esto reduce ruido. En un cluster con muchas VMs, un rescan global puede enseñarte información que no tiene nada que ver con tu problema actual. Si estoy mirando la VM 120, quiero empezar por la VM 120.
Luego, si la cosa huele a problema general de storage, amplio el radio.
Me gusta esta forma de trabajar porque evita diagnósticos grandilocuentes. Una VM rara no implica que el cluster esté roto. Un storage inactivo no implica que todos los discos estén perdidos. Una salida fea no implica desastre. Hay que estrechar el cerco.
discos unused: ni basura automática ni tesoro sagrado#
En Proxmox, un disco puede quedar asociado a una VM como unused. Esto pasa cuando quitas un disco de la configuración sin borrarlo del storage, cuando restauras, cuando mueves cosas o cuando alguna operación no termina como esperabas.
La línea suele tener este aspecto:
| |
Ese disco existe, pero no está conectado como scsi0, virtio0 o similar. Puede ser una oportunidad para recuperar datos. También puede ser un resto que ocupa espacio sin aportar nada.
Mi regla es no borrar un unused el mismo minuto en que lo descubro. Primero miro fecha, tamaño, VM, backups y contexto. Si el disco apareció después de una migración o restauración, espero a confirmar que la VM arranca bien y que no falta nada. Si lleva semanas ahí y tengo backup validado, entonces lo limpio.
El rescan ayuda a encontrar estas piezas, pero no decide por ti.
cuando el tamaño no encaja#
Otro uso cómodo de qm disk rescan es refrescar tamaños. A veces amplías un volumen, restauras desde un backend o hay una diferencia entre lo que Proxmox cree que mide un disco y lo que el storage expone.
Antes de tocar nada dentro del invitado, reviso la configuración:
| |
Busco las líneas de disco.
| |
Luego cruzo con storage. Si Proxmox no está viendo bien el tamaño, qm disk rescan --dryrun puede mostrarme que hay algo pendiente de actualizar. Si el tamaño ya está bien en Proxmox pero el sistema invitado no lo ve, el problema baja al invitado: particiones, LVM, filesystem o la herramienta que toque.
Separar esas capas evita perder tiempo. No es lo mismo “Proxmox no ve el tamaño” que “Linux no ha extendido la partición”.
el caso del storage inactivo#
La captura enseña un caso útil: local-lvm aparece inactivo. Esto suele pasar en clusters donde una definición de storage existe, pero no todos los nodos tienen ese backend disponible. También puede quedar como residuo de instalaciones antiguas.
El error no such logical volume pve/data suena peor de lo que a veces es. Si tus VMs importantes viven en RBD o en otro storage activo, quizá no hay impacto directo. Pero sí hay deuda de configuración. Cada vez que una herramienta recorre storages, ese backend inactivo puede meter ruido.
Yo lo leo así:
- si el storage debería existir, hay que arreglar LVM
- si el storage ya no se usa, hay que limpiar la definición
- si solo aplica a otros nodos, hay que revisar restricciones de nodos
- si el error aparece durante una incidencia, no lo ignoro
Lo peligroso es normalizar errores porque “siempre salen”. Esa frase en un homelab suele ser la antesala de una tarde bastante tonta.
lo que miro antes de borrar nada#
Cuando aparece un disco sobrante, mi checklist es corto.
| |
Después miro backups. No me basta con saber que hay backups. Quiero saber si hay un backup reciente y si alguna vez he restaurado algo de ese flujo. Backup que nunca has probado es fe con compresión.
También miro si la VM tiene snapshots. Borrar discos o tocar storage sin entender snapshots es una forma bastante eficaz de complicarte el día.
Y si la VM está en HA, reviso HA. No porque qm disk rescan sea una operación de disponibilidad como tal, sino porque cualquier acción posterior sobre discos puede cruzarse con migraciones, reinicios o mantenimiento del recurso.
cuándo ejecuto sin dry-run#
Ejecuto sin --dryrun cuando se cumplen tres condiciones.
Primero, entiendo qué va a cambiar.
Segundo, el storage implicado está sano o al menos sé por qué no lo está.
Tercero, tengo una salida razonable si algo no encaja.
Entonces sí:
| |
Si estoy haciendo limpieza global y ya he revisado el cluster, puedo lanzar el rescan sin VMID. Pero para diagnóstico de una máquina concreta, prefiero acotar.
Lo que no hago es ejecutar comandos globales para ver si “se arregla”. Esa frase es cómoda, pero en almacenamiento me parece una mala brújula. Si no sabes qué quieres que cambie, quizá todavía estás en fase de observación.
cómo encaja con la interfaz web#
La web de Proxmox muestra los discos de una VM y permite añadir, separar o borrar. La uso mucho. Pero cuando hay una discrepancia entre lo que veo y lo que creo que debería existir, la terminal me da una lectura más directa.
La interfaz es buena para operar. qm disk rescan --dryrun es bueno para preguntar.
No los veo como mundos separados. Normalmente hago las dos cosas. Miro la VM en la web para entender la forma visual. Luego bajo a terminal para confirmar storage, configuración y rescan. Si todo encaja, vuelvo a la web o sigo por CLI según la tarea.
La manía de hacerlo todo desde un único sitio acaba creando puntos ciegos. Proxmox tiene una interfaz decente y una CLI potente. Usar ambas no te hace menos purista. Te hace menos propenso a confundirte.
problemas que no arregla#
qm disk rescan no repara un backend roto. Si Ceph está mal, hay que mirar Ceph. Si CIFS no monta, hay que mirar red, credenciales y servidor. Si LVM está roto, hay que mirar LVM. El rescan no sustituye esa investigación.
Tampoco arregla un filesystem dentro del invitado. Si el disco ya existe y el sistema invitado no arranca, el problema puede estar dentro de la VM. Ahí toca consola, logs de arranque, fsck si procede y bastante calma.
Y no decide qué discos puedes borrar. Detectar un unused no equivale a permiso para limpiar. A veces ese disco es justo lo que te salvaría si descubres que te falta una partición.
mi conclusión#
qm disk rescan --dryrun es una herramienta de prudencia. Me deja pedirle a Proxmox que vuelva a mirar el storage sin comprometer cambios en caliente. Cuando la salida está limpia, avanzo. Cuando la salida enseña un storage inactivo, un disco sobrante o un tamaño raro, ya tengo una pista concreta.
No es el comando más vistoso de Proxmox. Mejor. Los comandos útiles de verdad suelen ser así: pequeños, secos y buenos para cortar niebla.
En mi rutina queda justo después de pvesm status y qm config. Primero sé qué storages existen. Luego sé qué discos cree tener la VM. Después pido un rescan en modo seguro. Si esas tres piezas encajan, ya puedo tocar almacenamiento con bastante menos teatro.