Hay comandos que parecen un trámite y luego están los que te evitan una noche de mierda. pveversion -v está en el segundo grupo.
Yo lo uso antes de actualizar un nodo Proxmox, antes de reiniciarlo y también cuando algo ya huele raro y quiero saber si el problema viene de una capa más aburrida de lo que me gustaría admitir. Porque sí, en homelab nos encanta echarle la culpa a Ceph, a Corosync, al storage compartido o a esa VM caprichosa que siempre aparece en el momento menos elegante. Pero muchas veces el drama empieza antes, en algo tan poco glamuroso como una versión que no cuadra, un kernel viejo todavía dando vueltas o un paquete medio roto que nadie miró con calma.
pveversion -v no es un dashboard. No te va a dibujar nada bonito. No tiene el encanto de una gráfica. Lo que hace es mejor. Te escupe la realidad del nodo en texto plano, sin maquillaje, y te obliga a leerla.
A mí eso me viene muy bien.
por qué le doy tanta importancia a una salida tan fea#
Porque Proxmox es muy agradecido cuando todo está razonablemente alineado, pero se vuelve bastante más desagradable cuando empiezas a mezclar estados distintos dentro del cluster. Un nodo con un kernel actual, otro con varias versiones viejas colgando, otro con una dependencia rara o un paquete instalado a medias. Nada de eso garantiza un desastre inmediato, pero sí cambia el tipo de mantenimiento que me permito hacer.
La diferencia importante no es entre “funciona” y “no funciona”. La diferencia importante es entre “entiendo el estado real del nodo” y “voy a tocar esto confiando demasiado en mis recuerdos”.
Yo ya he aprendido a no confiar tanto en mis recuerdos con Proxmox. La interfaz web ayuda mucho, claro. Pero la web no siempre te enseña con claridad si el host arrastra restos de kernels anteriores, si el stack base coincide con el resto del cluster o si hay una línea fea que conviene tomar en serio antes de seguir adelante.
pveversion -v sí.
una captura real que resume bastante bien por qué lo miro#
La siguiente captura sale de una revisión real en tres nodos de mi cluster. Está saneada en nombres y detalles internos, pero la lógica es la misma que uso en casa antes de una actualización.
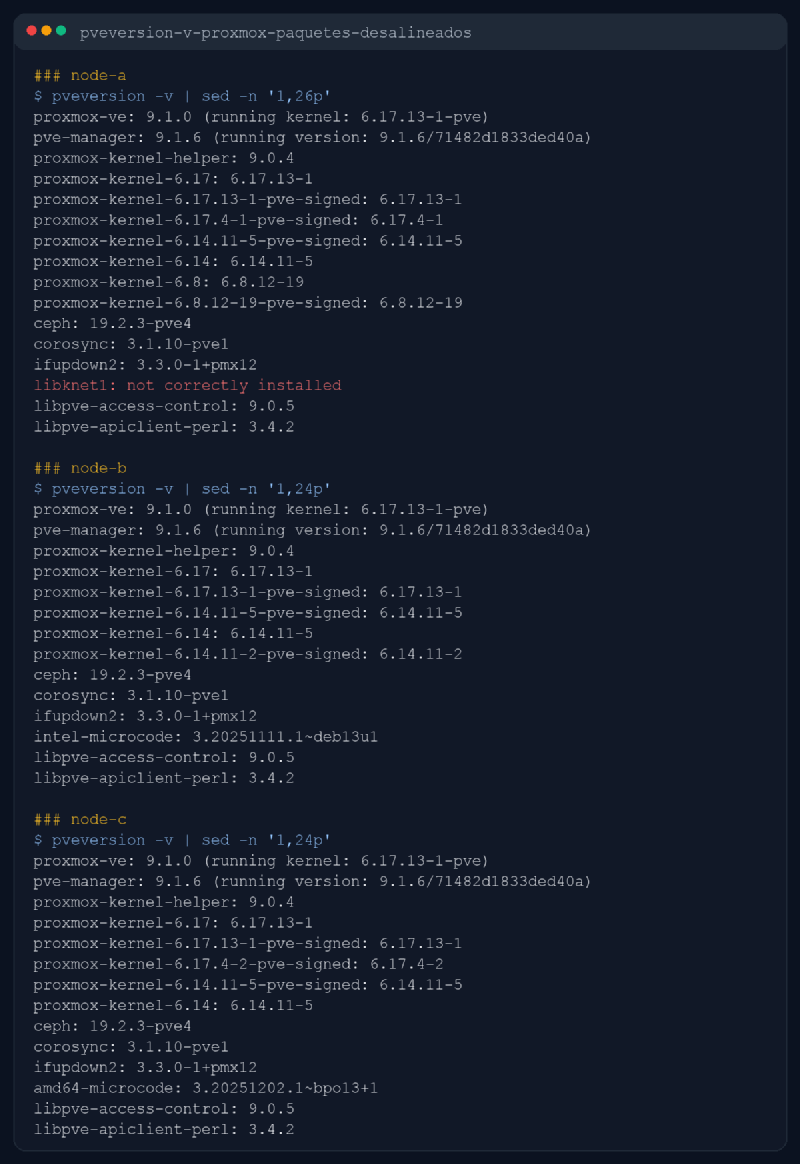
Lo primero que se ve es tranquilizador. Los tres nodos están en Proxmox VE 9.1.0 y los tres corren pve-manager 9.1.6. Bien. Eso me da una base bastante razonable para pensar que no tengo un Frankenstein a medio actualizar.
Pero luego empiezan los matices, que son justo lo que busco aquí.
En un nodo aparece una línea que me interesa bastante más de lo que parece a simple vista.
libknet1: not correctly installed
Eso no lo trato como una curiosidad. Tampoco lo trato como una tragedia automática. Lo trato como una señal de que este nodo merece más atención antes de hacer el valiente.
Y ahí está la gracia del comando. No necesito que todo vaya mal para que me sea útil. Me basta con que me enseñe una inconsistencia, una duda o una pieza fuera de sitio.
qué miro primero cuando lanzo pveversion -v#
proxmox-ve y pve-manager#
Empiezo por arriba del todo.
proxmox-ve me da la versión del meta paquete y además me recuerda qué kernel está corriendo en este momento. pve-manager me dice la versión de la capa principal de gestión. Si estas dos líneas ya vienen torcidas respecto al resto del cluster, no necesito mucha filosofía extra. El nodo no está alineado y toca averiguar por qué.
Cuando las veo iguales entre nodos, no cierro el caso. Solo paso al siguiente nivel.
el kernel en uso#
Aquí no busco una verdad absoluta. Busco contexto.
Me interesa saber si el kernel que corre el nodo es el esperado y si tiene sentido con el resto de paquetes instalados. Un host puede tener varios kernels instalados y seguir funcionando perfectamente. De hecho es lo normal. Lo que me preocupa es cuando el kernel en uso parece demasiado antiguo frente al estado general del nodo o cuando hay mezcla de series que no recuerdo haber dejado así.
En mi experiencia, los líos llegan más por suposiciones que por complejidad técnica. Das por hecho que el host levantó con el último kernel, luego no, luego reinicias sin mirar bien y te llevas una sorpresa que podrías haber evitado en diez segundos.
los paquetes base del stack#
Después bajo la vista por líneas como corosync, ifupdown2, ceph, proxmox-kernel-helper, librerías de cluster y demás piezas centrales. No porque espere memorizar cada versión exacta, sino porque sé reconocer cuándo algo se sale del dibujo normal.
Aquí me interesa más el patrón que el número aislado.
Si dos nodos vienen limpios y el tercero enseña una línea rara, ese tercero ya no es un nodo rutinario. Ya es un nodo con historia. Y los nodos con historia son los que me obligan a ir más despacio.
la línea fea no siempre es la más dramática, pero sí la más útil#
En la captura, la estrella accidental es libknet1: not correctly installed.
Esa línea me gusta poco, pero me gusta haberla visto antes de tocar nada.
knet forma parte de la base de comunicaciones del cluster. Si una librería relacionada con eso aparece como mal instalada, no me interesa seguir con la idea de “bueno, total, solo iba a hacer un apt full-upgrade rápido”. Igual luego no es nada grave. Igual es un estado transitorio, un paquete a medio configurar o un artefacto de una actualización incompleta. Pero la cuestión no es esa. La cuestión es que ya no estoy trabajando con información limpia.
Y cuando la información no es limpia, mi norma es sencilla. Primero aclaro el estado. Luego actualizo.
Esto parece conservador, pero me ha ahorrado más de un cabreo.
qué diferencias entre nodos me parecen normales#
No todo lo que cambia entre hosts me preocupa.
Por ejemplo, me parece totalmente razonable ver distintos paquetes de microcódigo según el hardware. Un nodo Intel y otro AMD no van a enseñar exactamente lo mismo. También es normal que la lista de kernels instalados no sea calcada si el historial de reinicios no ha sido idéntico o si un nodo todavía conserva una versión anterior por prudencia.
Eso no me inquieta por sí solo.
Lo que sí miro con recelo es esto.
- errores explícitos de instalación
- versiones del stack principal que no cuadran con el resto del cluster
- paquetes clave ausentes donde deberían estar
- mezcla rara entre el kernel en uso y las versiones realmente instaladas
El objetivo no es aspirar a una simetría perfecta. El objetivo es distinguir entre variedad razonable y desorden acumulado.
el error más típico al leer este comando#
Mirarlo como si fuera un inventario y no un diagnóstico.
Mucha gente lanza pveversion -v, ve una pared de texto y se queda con la sensación de que “todo parece estar ahí”. Para mí no va de eso. No quiero confirmar que existen paquetes. Quiero cazar anomalías.
Por eso no leo la salida con calma administrativa. La leo con desconfianza.
Preguntas que me hago siempre:
- ¿coincide lo importante con el resto de nodos?
- ¿hay alguna línea que no esperaba ver?
- ¿hay algo que me obligaría a explicar demasiado si siguiera ahora mismo?
Si la respuesta a la tercera es sí, paro.
En Proxmox tengo una regla muy simple. Si para seguir necesito contarme una historia tranquilizadora, todavía no estoy listo para seguir.
cómo lo cruzo con otras comprobaciones antes de actualizar#
pveversion -v me parece muy rentable solo, pero gana bastante cuando lo cruzo con otras tres miradas.
uname -r#
Sí, la versión del kernel ya aparece arriba, pero me gusta comprobarla rápido cuando estoy trabajando en modo mecánico y quiero asegurarme de que no estoy mezclando ideas de memoria con el estado real del host.
proxmox-boot-tool#
Lo conté en detalle en proxmox-boot-tool en Proxmox: cómo reviso kernels y arranque antes de reiniciar. Para mí tiene mucho sentido mirar ambas cosas juntas. pveversion -v me enseña qué hay instalado. proxmox-boot-tool me ayuda a ver qué está realmente listo para el próximo arranque cuando ese flujo aplica en el host.
Las dos respuestas no son iguales y conviene no mezclarlas.
pvecm status#
Si voy a tocar un nodo de cluster, quiero saber no solo cómo está el software de ese host, también cómo está respirando el conjunto. Lo mínimo es confirmar quorum limpio y una membresía coherente.
apt list --upgradable#
Esto me ayuda a bajar la conversación a tierra. Una cosa es ver lo que está instalado y otra ver lo que está pendiente. Si pveversion -v me enseña una base rara y además tengo una cola de paquetes importante esperando, ya sé que no estoy delante de un mantenimiento trivial.
lo que más me ha enseñado este comando con el tiempo#
Que los nodos rara vez se estropean de golpe. Antes suelen avisar. El problema es que avisan en un idioma feo.
Una línea que no cuadra. Un paquete marcado como mal instalado. Un kernel viejo que sigue ahí. Una diferencia entre hosts que nadie recuerda ya de dónde salió. Nada de eso suena heroico. Pero es exactamente el tipo de detalle que distingue un cluster cuidado de un cluster que funciona por inercia.
Yo no quiero un homelab que funciona por inercia. Ya bastante inercia hay en la vida normal.
Además, pveversion -v me obliga a una disciplina útil. Me fuerza a mirar el host como sistema, no solo como contenedor de VMs. Cuando paso demasiado tiempo pensando en servicios y muy poco pensando en la base, acabo pagando intereses.
cuándo me hace frenar en seco#
Hay varias señales que para mí convierten un update en una mala idea, al menos de momento.
errores explícitos en paquetes sensibles#
Si el comando me dice que algo no está correctamente instalado y encima afecta al stack de cluster o red, no sigo como si nada.
diferencias gordas entre nodos que no sé explicar#
No me molesta que haya matices. Me molesta no entenderlos.
demasiados kernels acumulados sin contexto claro#
No por estética. Porque muchas veces eso delata reinicios pendientes, limpiezas postergadas o una historia de mantenimiento poco consistente.
mezcla entre confianza alta y memoria difusa#
Esta es muy humana. Me noto pensando “seguro que este nodo estaba bien”. En ese punto dejo de fiarme de mí mismo y vuelvo al texto.
cuándo sí sigo tranquilo#
Cuando veo que el nodo está alineado con el resto en lo importante, que el kernel actual tiene sentido, que no hay errores de instalación y que cualquier diferencia está justificada por hardware o por historial conocido.
No necesito perfección. Necesito contexto.
En ese escenario sí me siento cómodo avanzando al resto del preflight y, si todo encaja, lanzando la actualización.
mi rutina real antes de tocar un nodo#
No hago veinte comprobaciones. Hago pocas, pero me las creo.
pveversion -vpvecm statusha-manager statussi el nodo participa en HAproxmox-boot-tool kernel listcuando toca reinicio- inventario local con
qm listypct list
Con eso suelo tener una foto suficientemente honesta para decidir si sigo o si hoy no toca ponerse creativo.
Y una cosa importante. A veces el mejor resultado de pveversion -v no es confirmar que todo está bien. A veces es pillarte una rareza a tiempo. Eso también es una victoria, aunque retrase el update media hora.
no todo warning merece pánico, pero casi todos merecen atención#
Creo que ahí está la lectura correcta del comando.
Si alguien espera una herramienta que le dé un sí o un no, esta no es. pveversion -v te obliga a pensar un poco. A veces solo para confirmar que el nodo está limpio. A veces para detectar que no lo está tanto como creías.
A mí me gusta precisamente por eso. No infantiliza la revisión. Te pone delante la materia prima y te deja decidir si el nodo está en una situación aburrida, que es lo ideal, o si arrastra alguna pequeña biografía técnica que conviene respetar.
En homelab yo me fío mucho más de un mantenimiento aburrido que de uno valiente.
mi conclusión#
pveversion -v es de los comandos más rentables de Proxmox porque resume en muy poco tiempo algo que la interfaz web no siempre te deja ver con claridad. Qué corre el nodo, qué kernels tiene alrededor, qué piezas base están instaladas y si hay alguna línea que rompe la normalidad esperada.
Yo lo miro antes de actualizar porque prefiero descubrir las rarezas en texto que descubrirlas después de un reboot y dos cafés tarde. Si la salida está limpia, sigo. Si veo un not correctly installed, una diferencia rara o algo que me obliga a inventarme explicaciones, paro y reviso.
No me parece paranoia. Me parece mantenimiento con memoria.
Y en Proxmox, donde un cluster sano depende mucho de no dar por obvias las capas aburridas, eso vale bastante más que cualquier ritual de falsa confianza.
referencias#
- Documentación oficial de administración del host en Proxmox VE
- Package Repositories en la wiki oficial de Proxmox
- Post relacionado: Actualizar Proxmox sin ir a ciegas: el preflight real que hago antes de un apt full-upgrade
- Post relacionado: proxmox-boot-tool en Proxmox: cómo reviso kernels y arranque antes de reiniciar
- Post relacionado: Cómo reviso la salud de un cluster Proxmox en dos minutos antes de tocar nada