Hay comandos que parecen poca cosa y luego te acaban enseñando medio estado del sistema si los lees con un poco de mala leche. pvesm status es uno de esos. Mucha gente lo abre, confirma que hay varios active, ve porcentajes que no dan miedo inmediato y pasa a otra cosa. Yo ya no lo hago así.
Con los años he aprendido que el almacenamiento en Proxmox rara vez te avisa con un único dramatismo limpio. Más bien va dejando señales pequeñas. Un storage que sigue activo pero ya va demasiado lleno. Un local-lvm que aparece inactivo y no sabes si es normal o una chapuza heredada. Un backup server que aún aguanta, pero está más cerca del borde de lo que te gustaría admitir. Nada de eso suena a tragedia instantánea. Precisamente por eso conviene mirar bien.
A mí me gusta pvesm status porque concentra bastante verdad en muy poco espacio. No me lo cuenta todo, pero sí me dice dónde merece la pena detenerme. Y en homelab eso ya vale mucho. No quiero un ritual infinito de comprobaciones antes de cada cambio. Quiero detectar rápido dónde puede haber una historia fea esperando detrás de una salida aparentemente normal.
por qué sigo mirando este comando aunque tenga paneles más bonitos#
No es que desprecie la interfaz web. La uso muchísimo. Pero pvesm status me gusta por una razón muy concreta. Obliga a leer el almacenamiento como una suma de destinos y no como un bloque abstracto que pone “todo bien”.
Eso me ayuda a responder preguntas muy útiles.
- ¿Qué storages están disponibles de verdad?
- ¿Cuál va ya demasiado lleno?
- ¿Cuál está inactivo y debería darme contexto?
- ¿Qué mezcla real tengo entre local, compartido, backup y almacenamiento de cluster?
En una instalación pequeña o mediana, esa foto vale oro. Porque muchas decisiones operativas dependen de ella. Mover una VM, ampliar un disco, hacer backups, actualizar un nodo o simplemente decidir si hoy toca tocar almacenamiento o mejor dejarlo quieto. Todo eso cambia bastante cuando sabes leer bien la tabla.
la salida que me hizo volver a mirarlo con más respeto#
Esta captura sale de una comprobación real de esta madrugada, saneada para no enseñar nombres internos del lab.
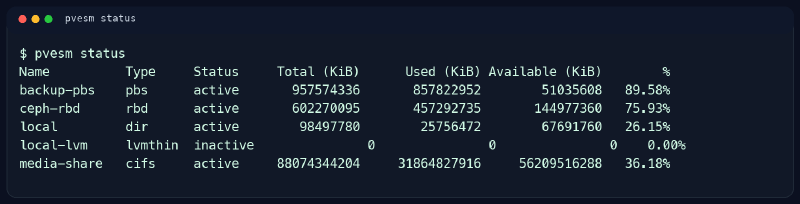
La tabla parece limpia. Y sin embargo, si me preguntas si esa salida me deja tranquilo, la respuesta es “a medias”.
No veo un incendio. Pero sí veo señales que condicionan lo que haría después.
backup-pbs al 89.58 por ciento#
Esto no significa “caída inminente”. Tampoco significa “todo bajo control”. Significa que el margen ya no es cómodo. En mi cabeza, cualquier destino de backup acercándose al 90 por ciento deja de ser un detalle y pasa a ser una conversación pendiente.
¿Por qué? Porque el backup siempre parece estable hasta el día que necesitas una cadena nueva, una retención distinta o una copia más grande de lo esperado. En ese momento descubres si estabas gestionando con margen o jugando al Tetris con datos críticos.
Yo aquí no entro en pánico. Pero sí bajo tolerancia al riesgo. Si veo PBS cerca de ese nivel, no me apetece combinar en la misma tarde nuevas tareas de backup, pruebas de restauración grandes y más inventos alrededor del storage. Primero entiendo el margen real. Luego ya decido si puedo seguir apretando.
ceph-rbd al 75.93 por ciento#
Aquí la lectura es más contextual. Un 75 por ciento no es automáticamente un problema. Depende del ritmo de crecimiento, del tipo de cargas y de cuánto colchón quieres reservar para movimientos, snapshots o recuperación de un nodo.
En un lab pequeño yo prefiero mirar ese número con bastante honestidad. Si el uso viene estable y sé que no hay crecimiento brusco a corto plazo, puede ser razonable. Si además sé que estoy a punto de crear discos nuevos, levantar pruebas o mover cargas, ese 75 ya me obliga a calcular mejor.
Ceph tiene una virtud y una trampa. La virtud es que te da flexibilidad muy buena. La trampa es que, por ser compartido y cómodo, invita a pensar que siempre habrá sitio para otra cosa más. Hasta que un día ya no.
local al 26.15 por ciento#
Este número me gusta más. No por fetichismo del espacio libre, sino porque me dice que el nodo todavía conserva bastante margen local para sistema, ISOs, plantillas o pequeños usos auxiliares sin ir justo.
Eso sí, el número por sí solo no basta. También me importa qué vive ahí. Un local medio vacío pero mal usado puede ser más molesto que uno más cargado y bien delimitado. Yo intento que el almacenamiento local tenga un papel claro y no se convierta en el cajón desastre donde van acabando restos de decisiones antiguas.
local-lvm inactivo al 0 por ciento#
Este es el tipo de línea que más me gusta comentar porque es justo donde mucha gente se equivoca. Ver inactive no siempre significa desastre. A veces significa simplemente que esa definición sigue en Proxmox, pero el volumen lógico que esperabas ya no existe o dejó de tener función real en ese nodo.
En la comprobación de esta madrugada, justo antes de la tabla salió además un mensaje muy poco poético y bastante útil. no such logical volume pve/data.
Eso ya te cuenta bastante historia. Proxmox sigue teniendo la referencia al storage local-lvm, pero el volumen fino que debería respaldarlo no está ahí. El error importante no es ver inactive. El error es no preguntarte si ese estado es esperado, heredado o peligroso.
Si ese storage ya no forma parte del diseño actual del nodo y todo lo relevante vive en otros sitios, puede no ser urgente. Si alguien todavía cree que puede desplegar discos ahí, la cosa cambia bastante.
Mi opinión aquí es clara. Un storage inactivo no se ignora. Se clasifica. O bien lo limpias de la configuración si ya no pinta nada, o bien arreglas la discrepancia si debería seguir existiendo. Lo que no haría es dejarlo eternamente en tierra de nadie y confiar en que nadie se confundirá nunca.
media-share activo al 36.18 por ciento#
Este es un buen ejemplo de por qué no me basta con ver active. Un share por red puede estar accesible y seguir mereciendo revisión si soporta procesos delicados o si el montaje tiene histórico de comportamientos caprichosos. El porcentaje aquí es cómodo, sí. Pero el contexto importa más que el numerito. Si ese destino forma parte de copias, medias o tareas automáticas, quiero saber qué pasa si se desmonta o va lento en el peor momento.
Después del susto reciente con validación de montajes NFS, yo ya miro cualquier storage de red con una mezcla sana de aprecio y sospecha.
el segundo paso que hago cuando algo no me cuadra#
Si pvesm status me deja una duda, no salto directo al dramatismo. Voy a la capa física y lógica del nodo. Para eso suelo mirar lsblk, lvs, vgs o pvs, según el caso.
Esta captura resume bastante bien esa segunda lectura.
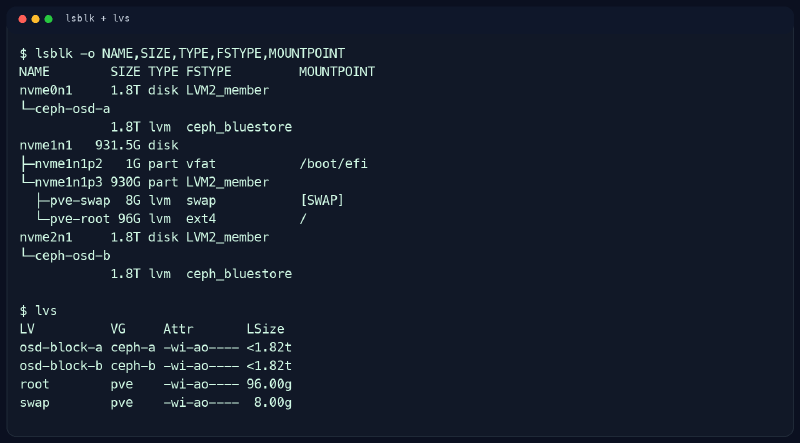
Aquí me gusta algo que a veces la gente evita porque parece menos glamuroso que hablar de Ceph o ZFS. Ver de dónde sale cada cosa baja muchísimo la tontería.
En este ejemplo se ve bastante claro.
- un NVMe sostiene el volumen
pve-rooty la swap - dos NVMe completos están dedicados a OSDs de Ceph
- no hay rastro de un
pve/dataactivo que justifiquelocal-lvm
Con esa foto, la línea local-lvm inactive deja de ser un misterio raro y pasa a ser una consecuencia lógica de la estructura real del nodo. Y esa diferencia importa mucho. Una cosa es un fallo emergente. Otra muy distinta es una referencia antigua que aún sigue en configuración.
cómo conecto la tabla con decisiones reales#
Esto es lo que más me interesa. No leer la salida como curiosidad, sino usarla para decidir mejor.
si PBS va alto, reviso retención antes de tocar nada más#
Cuando veo un backup server cerca del 90 por ciento, no pienso “ya lo miraré”. Pienso que tengo una deuda técnica esperando. Quizá no para esta misma madrugada, pero sí pronto. Reviso retenciones, snapshots huérfanos, backups que ya no necesito y, si hace falta, capacidad futura.
No me gusta acercarme al borde en backups porque el día que necesitas recuperar una VM o lanzar una copia nueva nunca coincide con el día en el que te sobra tiempo para limpiar.
si Ceph sube, reviso crecimiento antes de crear discos alegremente#
Ceph es muy agradecido hasta que te obliga a hacer cuentas. Yo intento anticiparme un poco. Si el porcentaje ya está en una zona respetable y sé que vienen nuevas VMs o expansiones de disco, no sigo empujando como si nada. Prefiero ajustar antes que ir dejando problemas para el yo de dentro de dos semanas.
si local-lvm está inactivo, decido si arreglarlo o borrarlo de la historia#
A mí me molestan bastante las medias verdades en infra. Un storage definido que ya no existe de verdad me parece justo eso, una media verdad. O lo necesitas y entonces lo restauras bien, o no lo necesitas y limpias la referencia. Lo que no me gusta es dejarlo en la UI y en la CLI como si aún formara parte del paisaje operativo normal.
si un storage de red está activo, verifico además si es fiable#
Aquí la lección reciente fue bastante clara. Un storage montado por red no solo tiene que aparecer active. También me interesa saber si el montaje está bien validado por los scripts que dependen de él. Porque una tabla bonita no evita un fallback local idiota si luego la automatización está mal escrita.
errores de lectura que veo mucho#
fijarse solo en active#
Es el error clásico. Active no significa sano, suficiente o bien pensado. Solo significa que en ese momento Proxmox lo ve disponible.
mirar el porcentaje sin contexto#
Un 75 puede ser perfecto o una mala noticia según el tipo de storage, el ritmo de crecimiento y el margen que de verdad necesitas. El porcentaje por sí solo no resuelve nada.
ignorar un inactive porque el nodo sigue funcionando#
Esto me parece un fallo muy humano. Si nada se ha roto todavía, damos por hecho que no hay urgencia. Puede que sea cierto. Pero eso no convierte el estado en irrelevante. Solo significa que aún no te ha explotado.
no bajar a lsblk o LVM cuando hace falta#
La tabla de Proxmox te dice mucho. No te lo dice todo. Cuando algo chirría, bajar una capa suele aclararlo rapidísimo. Y de paso te evita teorías absurdas.
mi checklist práctica para leer pvesm status sin engañarme#
Cuando abro este comando, suelo repasar lo siguiente.
- Qué storages importan de verdad para el día a día.
- Qué porcentaje ya me obliga a pensar en capacidad.
- Qué aparece
inactivey por qué. - Qué destinos de red dependen de montajes o de otro sistema.
- Si la mezcla entre local, compartido y backup sigue teniendo sentido.
No es una checklist de consultor. Es una forma de no leer la tabla como si fuera decoración.
dónde encaja esto con el resto del homelab#
Esta lectura del storage no vive separada del resto. Encaja bastante con varias piezas que ya he contado por aquí.
Si usas Ceph en casa, conviene tener bastante claro cuándo merece la pena y cuándo solo te roba horas. Si tus backups pasan por montajes de red, te interesa mucho no repetir el error que conté en Backups por NFS en homelab: cómo valido el montaje antes de llenar el disco local. Y si además trabajas con un cluster pequeño, toda esta lectura de storage afecta a cómo repartes las VMs y a cómo decides si hoy puedes tocar un nodo o mejor no.
Yo cada vez veo más claro que en homelab el almacenamiento no se administra bien solo con capacidad. También se administra con intención. Qué vive dónde, por qué, qué depende de red, qué depende de LVM, qué depende de Ceph y qué parte del dibujo ya quedó vieja pero sigue molestando en la configuración.
mi conclusión#
pvesm status no es un comando espectacular. Precisamente por eso me gusta. Porque obliga a mirar el almacenamiento sin adornos.
Si yo tuviera que resumir cómo lo uso, sería así. No miro solo qué está activo. Miro qué va justo, qué está raro, qué ya no encaja con la estructura real del nodo y qué decisión práctica debería cambiar por culpa de esa tabla.
La salida de esta madrugada no me dijo que tuviera un incendio. Me dijo algo más útil. Me recordó que el backup server ya merece una revisión seria, que Ceph aún está bien pero no para hacerse el despistado, que el almacenamiento local sigue teniendo margen y que local-lvm necesita o explicación definitiva o limpieza.
Y para mí ese es justo el valor del comando. No me da una verdad absoluta. Me da una conversación honesta con el estado real del lab. En un homelab de verdad, eso vale bastante más que cualquier sensación vaga de “parece que todo está bien”.
referencias#
- Storage en Proxmox VE
- LVM Thin Provisioning en Proxmox VE
- Ceph en Proxmox VE
- Post relacionado: Ceph en homelab: cuándo merece la pena y cuándo solo te roba horas
- Post relacionado: Backups por NFS en homelab: cómo valido el montaje antes de llenar el disco local
- Post relacionado: Cómo reparto las VMs en mi cluster Proxmox para no convertir un nodo en el pringado de la casa