Hay una zona de Proxmox que mucha gente mira solo cuando algo ya ha explotado. Las tareas recientes.
Yo intento mirarlas antes.
Cuando un nodo se comporta raro, una VM aparece apagada, un backup falla o una acción del panel no termina como esperaba, una de las primeras cosas que lanzo es esto.
| |
Es una forma rápida de preguntarle al nodo qué ha pasado hace poco. No lo que yo creo que pasó. No lo que recuerdo haber tocado mientras tenía tres pestañas abiertas. Lo que Proxmox ha registrado como tarea.
Y eso, en un homelab con varios nodos, automatizaciones, backups nocturnos y alguna VM rebelde, vale bastante.
la captura real de este post#
La salida de esta captura sale de un nodo real. He saneado el nombre del nodo y he recortado campos internos que no aportan nada para explicar la idea. Mantengo lo importante: tipo de tarea, estado, usuario, id y tiempos.
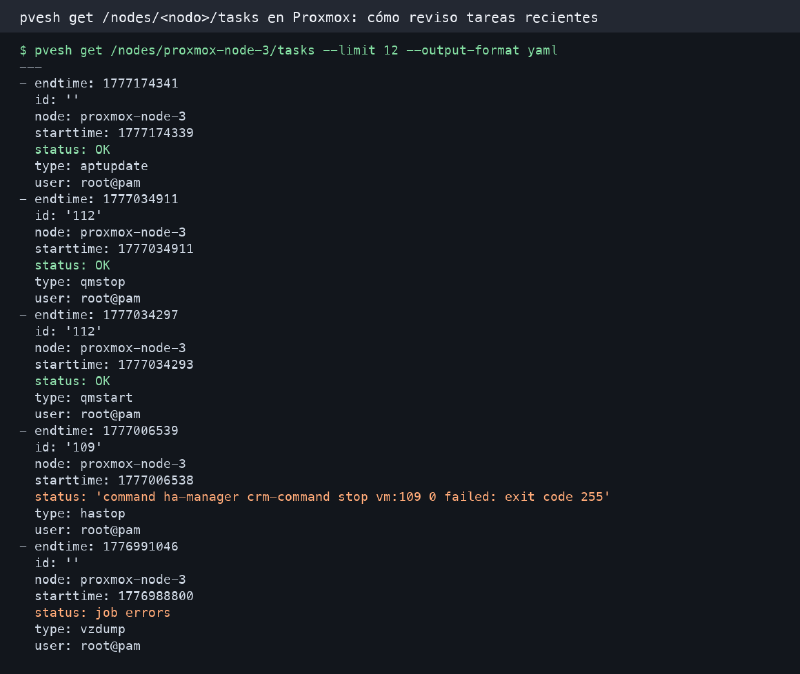
Me gusta porque enseña una mezcla bastante normal. Hay tareas OK, arranques y paradas de VM, un aptupdate, un fallo de HA y un backup con job errors.
Eso se parece mucho más a un laboratorio real que una lista impecable donde todo sale verde. En mi experiencia, los Proxmox de verdad tienen cicatrices pequeñas. La gracia está en saber cuáles importan.
por qué no me basta con mirar el panel#
El panel de Proxmox tiene una vista de tareas muy cómoda. La uso. No tengo ningún problema con la interfaz.
Pero cuando estoy por SSH, o cuando quiero guardar una evidencia rápida, o cuando el panel no me inspira confianza, prefiero pvesh. Me da una salida que puedo copiar, filtrar, guardar y comparar sin tocar el navegador.
En una incidencia, el panel puede hacerte mirar demasiado. Ves mil cosas. Te vas a storage, luego a una VM, luego a HA, luego a logs, luego vuelves atrás y de repente ya no sabes cuál era la pregunta original.
Con esta salida la pregunta es más simple.
¿Qué tareas recientes han terminado bien y cuáles no?
lo primero que busco: status#
La línea más importante de cada bloque es esta.
| |
O esta otra, menos amable.
| |
O una de estas frases largas que Proxmox suelta cuando algo de HA no ha ido bien.
| |
No todas las tareas fallidas tienen la misma gravedad. Un aptupdate fallido puede ser un repo caído, una llave rota o un nodo sin salida. Un vzdump con errores puede ser un backup parcial, una VM bloqueada o un storage que se desconectó. Un hastop fallido puede apuntar a una pelea con HA, estado bloqueado o una orden que no llegó como debía.
Lo que no hago es ignorarlo porque “parece que ahora va”. Si una tarea falló hace poco, la trato como pista hasta que la descarto.
type cuenta la historia corta#
El campo type es el titular.
| |
| |
| |
| |
Con esto ya sé por dónde empezar. Si veo varios qmstart y qmstop seguidos sobre la misma VM, sé que alguien o algo estuvo arrancando y parando esa máquina. Si veo vzdump, pienso en backups. Si veo aptupdate, pienso en repositorios. Si veo hastop, miro HA antes de inventarme problemas de storage o red.
Parece una tontería, pero me evita perseguir la avería equivocada.
Hace años habría visto una VM apagada y habría empezado a mirar consola, disco, cloud-init o logs internos. Ahora miro primero las tareas. Si el nodo me dice que hace diez minutos hubo un qmstop, ya tengo una pista mucho más directa.
id no siempre significa lo mismo#
En la captura aparece esto.
| |
Ahí el id apunta a la VM afectada. Fácil.
Pero también aparece esto.
| |
En tareas de nodo, el id puede venir vacío. No pasa nada. No es que falte información crítica. Simplemente no todas las tareas están asociadas a una VM o contenedor concreto.
La lectura correcta depende del type. Si es qmstart, qmstop, qmigrate o algo parecido, el id suele llevarte a una VM. Si es vzdump, puede venir más global según cómo se haya lanzado. Si es aptupdate, estás mirando una tarea del nodo.
No conviene leer campos sueltos sin contexto. Proxmox no está escribiendo una novela para humanos. Está exponiendo registros de tareas. Nosotros tenemos que ponerles orden.
usuario: root@pam no significa siempre una persona sentada#
En muchos homelabs casi todo aparece como root@pam.
| |
Eso no significa necesariamente que alguien haya entrado manualmente al panel y pulsado un botón. Puede ser un script, una tarea programada, una integración o una acción lanzada con credenciales de root.
En un entorno más cuidado, tendría usuarios separados para automatizaciones, backups y administración humana. En un homelab, seamos razonables, muchas veces eso llega tarde. Yo intento no engañarme con esta línea. Me sirve para saber el usuario Proxmox que ejecutó la tarea, no para reconstruir toda la intención detrás.
Si necesito saber quién lo lanzó de verdad, ya tengo que mirar más cosas. Historial de shell, scripts, cron, automatizaciones, logs del servicio que dispara la acción. Pero como primera pista, user ayuda.
tiempos: no mires solo el fallo, mira cuándo pasó#
starttime y endtime parecen aburridos hasta que una incidencia cruza varios sistemas.
| |
Los tiempos vienen como epoch. No son cómodos para leer a ojo, pero son perfectos para cruzar con logs.
Si un backup falló a una hora concreta y justo en ese rango tienes errores de NFS, Ceph, disco USB, red o una VM congelada, ya puedes construir una historia. Si los tiempos no coinciden, quizá estás mirando una casualidad.
Yo suelo convertirlos cuando necesito investigar en serio.
| |
En Linux usaría date -d @1776991046. En macOS uso date -r. Es una tontería pequeña hasta que estás comparando tres logs distintos y necesitas saber si las piezas encajan.
el caso del backup con job errors#
Un vzdump con job errors no lo dejo pasar.
| |
Puede que el backup haya salvado algunas VMs y fallado en una. Puede que el storage destino estuviera lento. Puede que una VM tuviera un snapshot colgado. Puede que el error sea conocido y asumido. Pero hasta que lo miro, no lo sé.
Mi siguiente paso suele ser abrir el log de esa tarea desde Proxmox o tirar del UPID si lo he dejado en la salida completa. En esta captura lo he quitado porque no aporta al lector y ensucia bastante, pero en una investigación real el UPID es oro.
La idea práctica es simple. Si veo vzdump con errores, no digo “ya miraré backups otro día”. Lo miro ahora o lo apunto como deuda clara. Los backups fallidos son el típico problema que parece administrativo hasta que el día malo te acuerdas de él con cariño y odio a la vez.
el caso de HA fallando al parar una VM#
La línea del hastop es más jugosa.
| |
Aquí Proxmox intentó parar una VM gestionada por HA y la orden no terminó bien. No significa automáticamente que HA esté roto entero. Tampoco significa que la VM esté perdida. Significa que hay una tarea concreta que falló y que merece cruzarse con el estado de HA.
Mi siguiente lectura sería ha-manager status, logs de HA y estado de la VM. Si además veo varios intentos fallidos cerca en el tiempo, sube mi sospecha. Una tarea fallida puede ser ruido. Varias tareas iguales fallando ya empiezan a oler a patrón.
Esto es justo lo que me gusta de pvesh get ... tasks. Te enseña repetición. Y la repetición en sistemas casi siempre cuenta algo.
por qué limito la salida#
Uso --limit 12 porque no quiero una sábana infinita.
| |
Doce tareas suelen bastar para ver qué ha pasado hace poco. Si necesito más, subo el límite. Pero de entrada prefiero una salida corta que pueda leer entera.
En incidencias, la longitud también es enemiga. Una lista de cien tareas te hace sentir que estás investigando mucho, pero muchas veces solo estás nadando en barro. Empiezo pequeño. Si veo una pista, profundizo.
cómo lo cruzo con otros comandos#
Si la tarea fallida es de backup, voy a logs de vzdump, storage y estado de la VM afectada.
Si es de HA, cruzo con ha-manager status en Proxmox y con las tareas de la VM.
Si es de arranque o parada, miro qm status <id>, configuración de la VM y eventos cercanos.
Si es aptupdate, miro repositorios, salida de apt update y versión de paquetes con pveversion -v.
Si el panel web está raro, lo cruzo con systemctl status pveproxy y con los logs de pveproxy.
La gracia no está en convertir un comando en religión. La gracia está en usarlo como índice. Te dice qué puerta abrir primero.
mi rutina de treinta segundos#
Cuando miro tareas recientes, sigo una rutina bastante mecánica.
Primero busco cualquier status que no sea OK.
Luego miro si el mismo type se repite varias veces.
Después miro si el mismo id aparece en varias tareas seguidas.
Luego cruzo tiempos con lo que estaba haciendo yo o con lo que disparan los cron.
Y por último decido si es ruido, deuda pendiente o problema activo.
No necesito resolverlo todo desde esa salida. Solo necesito clasificarlo bien. Si lo clasifico mal, pierdo tiempo. Si lo clasifico bien, el siguiente comando suele salir bastante claro.
lo que quitaría de la salida para leerla mejor#
La salida completa de Proxmox trae más campos, como upid, pid y pstart. Son útiles cuando vas a abrir el log exacto de una tarea o cuando estás depurando algo muy concreto. Para una lectura rápida, molestan más de lo que ayudan.
Por eso, para una chuleta diaria, me quedo con type, status, id, user, starttime y endtime.
Si quiero algo más limpio, puedo tirar de jq cuando uso JSON.
| |
No hace falta sofisticarlo demasiado. La idea es tener una lista legible de lo que Proxmox intentó hacer y cómo acabó.
lo que no te dice#
Esta salida no te explica la causa raíz. Te enseña síntomas registrados.
Un vzdump con errores no te dice si el problema fue el storage, la VM, la red o el timeout.
Un hastop fallido no te dice por sí solo si HA está mal configurado, si la VM estaba bloqueada o si hubo un problema transitorio.
Un qmstart correcto no te dice si el servicio dentro de la VM arrancó bien.
Aun así, me parece una de las lecturas más útiles cuando algo se queda a medias. Porque antes de buscar causas necesitas saber qué acciones ocurrieron de verdad.
En un homelab, la memoria humana es bastante mala. Tocamos cosas de noche, dejamos pruebas a medias, lanzamos backups, paramos una VM para mirar una tontería y al día siguiente juraríamos que no hicimos nada.
Proxmox no tiene ese problema. Sus tareas recientes son bastante menos imaginativas que nosotros. Y por eso conviene escucharlas.