Hay días en los que no quiero abrir el panel de Proxmox. No porque la interfaz sea mala, sino porque a veces necesito una lectura más seca del nodo antes de contaminarme con colores, gráficas y esa falsa tranquilidad que da ver una pantalla cargada.
Para eso uso bastante este comando.
| |
pvesh es de esas herramientas que parecen feas hasta que te salva media tarde. Es la API de Proxmox desde la terminal. Lo que ves en la web, con más o menos capas, sale de ahí. Y cuando estoy tocando un nodo concreto, me gusta tener una foto rápida de CPU, memoria, kernel, versión de PVE, disco raíz, swap y uptime sin depender de que el navegador esté fino.
No lo uso como sustituto de una monitorización seria. Para eso prefiero Grafana, Netdata, Beszel o lo que toque según el laboratorio. Lo uso como linterna. Entro, miro lo justo, decido si el nodo está para tocarlo o si me está diciendo que me aparte.
la captura real de este post#
Esta salida viene de un nodo real de mi laboratorio. He saneado el nombre del nodo y he quitado detalles que no aportan nada al lector. El resto es una foto bastante honesta del tipo de información que miro.
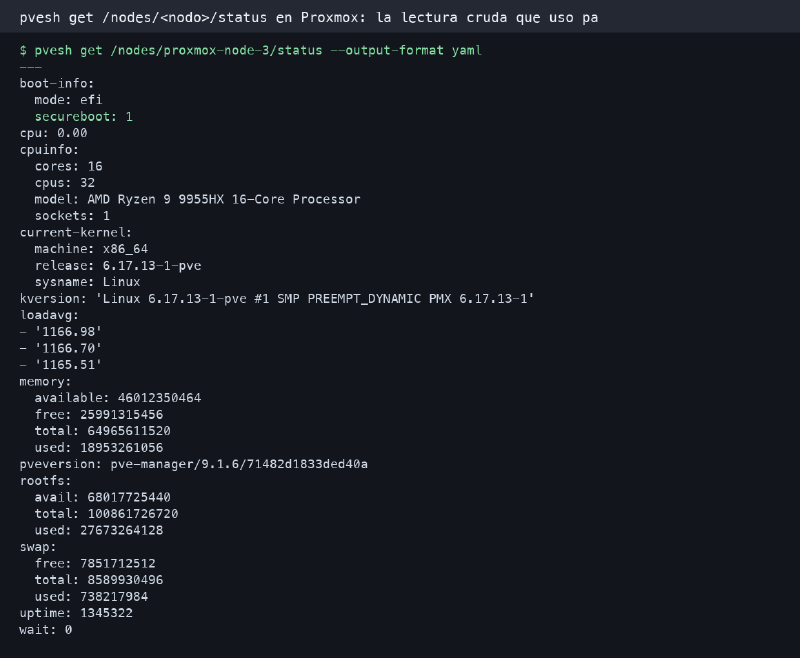
Me gusta esta captura porque no es perfecta. De hecho tiene una línea rara que llama la atención enseguida, el loadavg disparado. Justo por eso me sirve. Las capturas demasiado limpias enseñan poco. En un homelab real siempre hay alguna cosa torcida, un servicio haciendo ruido, una métrica absurda o un estado que obliga a cruzar datos antes de sacar conclusiones.
por qué miro esto antes de tocar nada#
Cuando voy a reiniciar una VM, mover una carga o actualizar un nodo, no quiero asumir que el nodo está sano porque el panel responde. Quiero verlo.
La salida de status me da varias pistas en una sola llamada.
- qué kernel está arrancado
- qué versión de Proxmox está corriendo
- cuánta memoria queda de verdad
- cuánto disco raíz queda libre
- si hay swap usada
- cuánto lleva levantado el nodo
- qué carga media está reportando
No es un diagnóstico completo. Es el primer filtro.
Si aquí veo memoria al límite, raíz casi llena, swap ardiendo o una versión de kernel que no coincide con lo que esperaba, paro. No hago el típico “reinicio y ya veremos” porque eso en Proxmox suele ser la forma elegante de regalarte una hora de barro.
pveversion y kversion, la pareja que siempre cruzo#
Las dos líneas que busco muy pronto son estas.
| |
La versión de Proxmox me dice dónde estoy a nivel de paquetes de gestión. El kernel me dice qué está ejecutando realmente el nodo. Parece una diferencia de matiz, pero no lo es.
Después de actualizar un cluster, puedes tener paquetes nuevos instalados y un kernel viejo todavía cargado porque no has reiniciado. También puedes tener un nodo que se quedó a medias respecto al resto. En un cluster pequeño esto no siempre rompe nada al instante, pero sí mete ruido. Y si luego aparece un problema de red, almacenamiento o HA, ese ruido hace que todo sea más difícil de leer.
Por eso me gusta mirar estas dos líneas juntas. Si voy a hacer mantenimiento, quiero saber si estoy ante un nodo ya reiniciado con el kernel esperado o ante un nodo que todavía arrastra una parte de la actualización anterior.
Lo enlazo mentalmente con el post de pveversion -v en Proxmox, que uso cuando necesito bajar al detalle de paquetes. status me da la foto corta. pveversion -v me da la lista larga cuando algo huele raro.
memoria, swap y el error de mirar solo free#
La parte de memoria de esta salida es más útil de lo que parece.
| |
Lo primero que miro es available, no free. En Linux, free puede engañar bastante porque el sistema usa memoria para caché y eso no significa que esté en problemas. available suele contar mejor lo que el sistema podría entregar a procesos nuevos sin empezar a sufrir.
En este nodo, la memoria no me preocupa. Hay margen. La swap tiene algo de uso, pero no está ni cerca de ser una hoguera. Aun así, me gusta verla. Si un nodo empieza a usar swap de forma seria mientras aloja VMs sensibles, ya no lo trato igual. No significa que vaya a caer, pero sí que no le meto más carga con alegría.
Mi regla casera es simple. Si available está cómodo y la swap apenas se toca, puedo seguir mirando otras cosas. Si available cae mucho y la swap sube, dejo de pensar en Proxmox como panel bonito y empiezo a pensar en el nodo como Linux bajo presión.
rootfs, el disco pequeño que fastidia cosas grandes#
Otra sección que no ignoro jamás.
| |
El disco raíz no es el almacenamiento de las VMs, o al menos no debería serlo en una instalación decente. Pero si se llena, el nodo se puede volver desagradable. Logs, actualizaciones, cachés, paquetes, backups mal apuntados, cualquier tontería puede comerse / y convertir una tarea normal en una persecución absurda.
Aquí hay margen. Unos 68 GB disponibles sobre 100 GB. Bien.
Si esta línea estuviera al 90 por ciento, no actualizaría nada antes de limpiar. Tampoco movería cargas importantes. Primero entendería qué lo está llenando. En Proxmox, un rootfs lleno es una de esas averías tontas que parecen otra cosa hasta que miras el dato correcto.
uptime y el sesgo del nodo que “lleva mucho sin molestar”#
| |
El uptime aquí es largo. Eso no es ni bueno ni malo por sí solo.
Durante años hubo una especie de orgullo raro con tener servidores con uptimes eternos. En un homelab moderno me parece una métrica bastante pobre si la lees sola. Un nodo con mucho uptime puede ser estable, sí. También puede ser un nodo que lleva semanas esperando un reinicio después de actualizaciones pendientes.
Yo uso el uptime como contexto. Si veo kernel viejo, paquetes nuevos instalados y uptime largo, ya sé qué puede estar pasando. Si veo uptime largo pero versiones coherentes y sin actualizaciones pendientes, no me obsesiono.
La clave es no convertir el uptime en medalla. Un Proxmox que nunca reinicias no es automáticamente más serio. A veces solo es un Proxmox al que todavía no le has cobrado la deuda.
la línea rara: loadavg por las nubes#
Esta captura tiene una línea que parece gritar.
| |
Si lees eso y piensas “este nodo está muerto”, te entiendo. Es la reacción normal. Pero aquí es donde hay que cruzar datos.
La CPU sale a cero en esta foto. wait también sale a cero. La memoria está cómoda. El nodo responde. Eso no cuadra con una carga real de más de mil procesos peleando por CPU o I/O.
¿Qué hago entonces? No saco una conclusión heroica desde una sola salida. Abro otra terminal y miro top, htop, uptime, ps, métricas del agente y logs del nodo. Si todo lo demás está tranquilo, trato esa lectura como una señal rara que merece seguimiento, no como incendio confirmado.
Este punto me parece importante porque en homelab hay dos formas de perder tiempo. Ignorar alertas reales y perseguir fantasmas. Las dos cansan. Una salida como esta te obliga a distinguir entre dato raro y problema real.
CPU a cero no significa “todo perfecto”#
| |
Bonito, pero tampoco hay que enamorarse.
La CPU instantánea puede salir baja justo en el momento de la consulta. Eso no significa que el nodo no haya sufrido hace cinco minutos. Tampoco significa que una VM no esté atascada por dentro. Para eso miro histórico, tareas, logs y métricas por VM.
Aun así, estas líneas son útiles como primera lectura. Si cpu y wait están bajos mientras memoria y disco van cómodos, el nodo no parece estar en presión bruta en ese instante. Eso me permite moverme con algo más de calma.
Si wait estuviera alto, la historia cambia. En Proxmox, un iowait alto suele ser el principio de una tarde antipática. Puede ser storage local, NFS, Ceph, backups, una VM escribiendo demasiado o un disco con ganas de jubilarse. Pero ya no estás en el terreno de “la web va rara”. Estás mirando posible bloqueo de I/O.
cuándo uso este comando#
Lo uso en cuatro momentos.
Antes de actualizar un nodo, para confirmar versión, kernel, memoria y disco raíz.
Antes de reiniciar algo que vive en ese nodo, para saber si el host ya viene tocado.
Después de una incidencia, para dejar una foto rápida del estado base.
Cuando el panel web responde lento y quiero separar navegador, pveproxy y salud real del host.
No es el comando más vistoso de Proxmox. No tiene el dramatismo de ceph -s, ni la claridad de pvecm status, ni la utilidad directa de qm list. Pero se ha ganado un sitio en mi rutina porque responde a una pregunta muy práctica.
¿Este nodo está en condiciones razonables para que yo siga tocando cosas?
mi lectura rápida#
Si tuviera que leer esta salida en treinta segundos, haría esto.
Primero miro pveversion y kversion. Quiero saber si el nodo está donde creo que está.
Luego miro memoria y swap. Si hay presión, paro.
Después miro rootfs. Si / está cerca del límite, no actualizo ni me pongo creativo.
Luego miro loadavg, cpu y wait juntos. Nunca separados.
Por último miro uptime para entender si estoy ante un nodo recién reiniciado o ante uno que lleva tiempo acumulando historia.
Esa lectura no sustituye a investigar, pero evita tocar a ciegas. Y tocar a ciegas un cluster Proxmox es una afición cara en horas, aunque no cueste dinero.
lo que no te dice#
También conviene tener claro lo que este comando no resuelve.
No te dice si Corosync está sano. Para eso prefiero pvecm status, corosync-quorumtool -s o corosync-cfgtool -s.
No te dice si el almacenamiento compartido está bien. Para eso miro pvesm status, ceph -s si aplica y los logs del backend.
No te dice si una VM está bien por dentro. Solo te habla del nodo que la aloja.
Y no te da histórico. Es una foto. Una foto útil, pero foto al fin y al cabo.
Aun con esas limitaciones, me gusta tenerlo cerca. En una incidencia real, muchas veces no necesito una novela. Necesito una lectura corta y fiable para decidir el siguiente movimiento. pvesh get /nodes/<nodo>/status me da justo eso.
No arregla nada por sí solo. Pero evita empezar por el sitio equivocado, que en Proxmox ya es media victoria.