Hay una diferencia bastante grande entre saber que un nodo Proxmox tiene VMs y saber qué VMs tiene ahora mismo, en qué estado están y cuánto están consumiendo. Parece una tontería hasta que vas a reiniciar, actualizar, mover una carga o investigar por qué un nodo está más cargado que los demás.
Para esa primera mirada uso mucho este comando.
| |
No tiene misterio. Le pido al nodo su lista de máquinas virtuales QEMU y Proxmox me devuelve una foto bastante útil. Estado, CPUs asignadas, memoria máxima, memoria usada, disco máximo, tráfico de red, uptime, tags y VMID.
La interfaz web lo enseña de forma más amable. Pero cuando estoy por SSH, o cuando quiero copiar una salida a una nota de mantenimiento, prefiero pvesh. Es más tosco, sí. También es más directo. En un homelab eso pesa mucho.
la captura real de este post#
La salida viene de un nodo real de mi laboratorio. He cambiado nombres, VMIDs y etiquetas para no enseñar detalles internos. También he recortado campos repetidos. Lo importante está ahí.
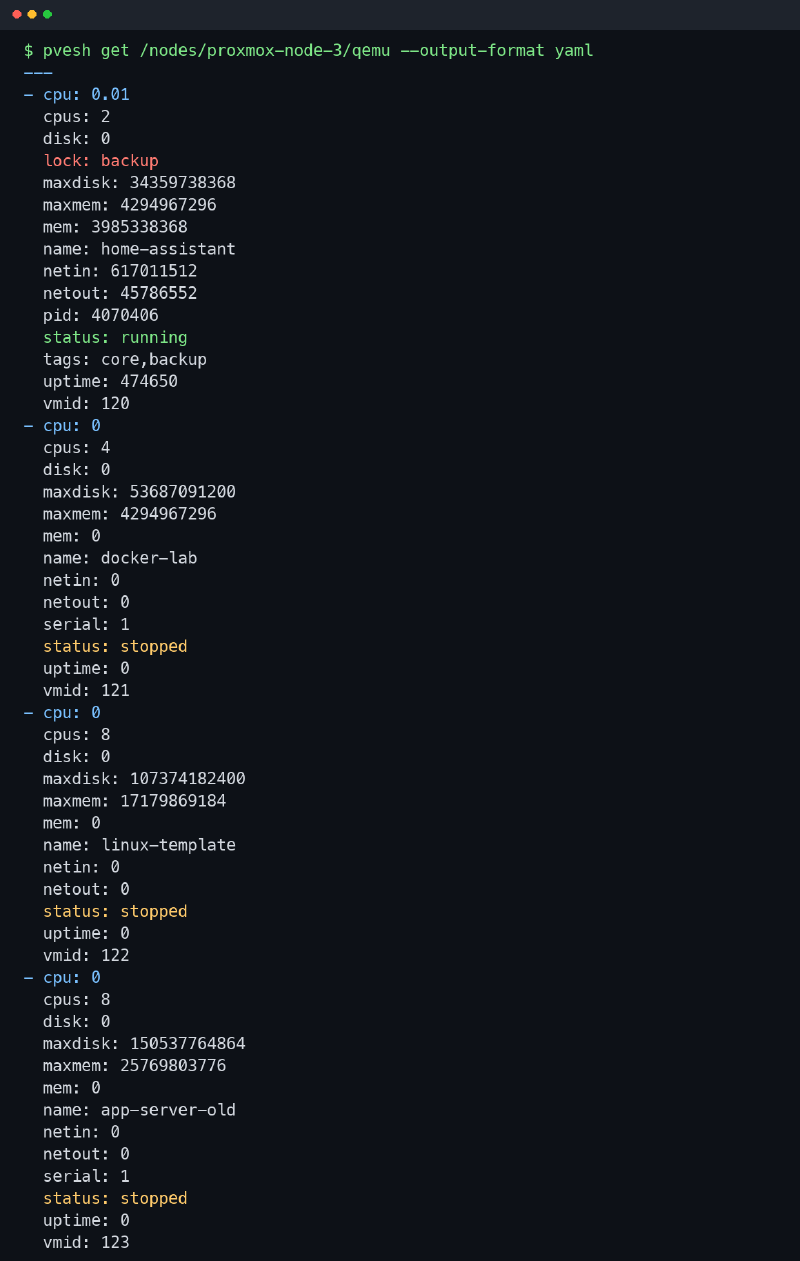
La captura enseña justo el tipo de mezcla que suelo ver en un nodo de casa. Una VM corriendo, varias apagadas, memoria asignada generosa en alguna máquina, otra con serial, otra con etiqueta. No es una lista perfecta de laboratorio de tutorial. Es una lista de máquinas que han ido apareciendo con el tiempo porque un homelab nunca se construye en línea recta.
por qué miro qemu antes de reiniciar un nodo#
Antes de tocar un nodo quiero saber qué se queda dentro. No me basta con recordar que “aquí no hay nada crítico”. La memoria humana es una base de datos lamentable cuando llevas meses moviendo VMs, probando servicios y cambiando prioridades.
La salida de pvesh get /nodes/<nodo>/qemu me responde varias preguntas rápido.
- qué VMs están encendidas
- qué VMs están apagadas pero siguen asignadas al nodo
- cuánta RAM tiene reservada cada una
- cuántas vCPU tiene configuradas
- si hay tráfico reciente de red
- si alguna VM tiene un lock
- qué VMID necesito para el siguiente comando
Ese último punto parece pequeño, pero no lo es. Muchas veces el siguiente paso es qm status, qm config, qm shutdown o qm migrate. Si ya tengo el VMID delante, no tengo que volver a mirar nada.
status es el primer filtro#
La columna que miro primero es status.
| |
O bien.
| |
No hay poesía aquí. Si una VM está running, tengo que tratarla como carga viva. Si está stopped, puede seguir importando, pero no está metiendo presión ahora mismo.
El error típico es mirar solo las VMs encendidas y olvidarse de las apagadas. Yo no lo hago. Una VM apagada también ocupa sitio mental y a veces ocupa mucho sitio en disco. Puede ser una plantilla vieja, una migración a medias, una prueba que nunca se limpió o una máquina que alguien espera recuperar dentro de dos meses.
Cuando un nodo tiene demasiadas VMs apagadas, no siempre es un problema técnico. Pero sí suele ser una señal de desorden. Y el desorden en Proxmox acaba saliendo por algún lado. Sale cuando buscas espacio, cuando migras, cuando haces backups o cuando intentas entender por qué tienes máquinas duplicadas.
vmid manda más que el nombre#
Los nombres ayudan, pero el VMID es lo que uso para actuar.
| |
En un homelab los nombres cambian. Hay nombres temporales que se vuelven definitivos por pura pereza. Hay máquinas que se clonaron y conservaron parte del nombre. Hay pruebas que empiezan como test-ubuntu y acaban alojando algo importante porque así somos, animales de costumbres malas.
El VMID, en cambio, es la referencia operativa. Cuando voy a revisar configuración, lanzo esto.
| |
Cuando quiero ver estado más concreto, esto.
| |
Y si tengo que buscar tareas recientes de esa VM, ya sé qué número filtrar mentalmente en la lista de tareas del nodo.
No digo que haya que ignorar los nombres. Digo que en una incidencia no quiero depender de nombres bonitos. Quiero IDs.
memoria máxima y memoria real#
La salida enseña dos campos que conviene no leer igual.
| |
maxmem es la memoria máxima configurada. mem es lo que Proxmox reporta como uso de la VM. En algunas máquinas sale con bastante sentido. En otras puede ser menos intuitivo según guest agent, ballooning y configuración interna.
Aun así, la pareja me sirve. Si veo una VM con 16 GB asignados y apagada, ya sé que si la enciendo va a cambiar el equilibrio del nodo. Si veo varias VMs con mucha memoria máxima, aunque estén tranquilas, sé que ese nodo no tiene margen infinito.
Esto me importa especialmente antes de concentrar cargas. Mover una VM pequeña no da miedo. Mover tres VMs con mucha RAM asignada a un nodo que ya está alegre es otra cosa.
Mi regla es simple. No miro solo el consumo instantáneo. Miro también lo que cada VM puede llegar a pedir. Proxmox no es magia. Si prometes más recursos de los que el nodo puede aguantar en el peor momento razonable, algún día te lo cobra.
CPUs asignadas no son CPUs usadas#
Otro campo que se malinterpreta mucho.
| |
cpus me dice cuántas vCPU tiene asignadas la VM. cpu me dice el uso que Proxmox ve en ese instante. Una VM con 8 vCPU y cpu: 0 puede no estar haciendo nada ahora. Pero sigue siendo una máquina configurada con permiso para pedir bastante.
En casa tendemos a sobredimensionar. “Le pongo 8 cores por si acaso”. Luego haces eso diez veces y acabas con un nodo que parece generoso en papel pero absurdo cuando varias cosas despiertan a la vez.
No me obsesiona sobreasignar vCPU. En homelab se puede hacer con cabeza. Pero cuando reviso un nodo y veo muchas VMs con más CPUs de las que realmente necesitan, lo apunto. No siempre lo arreglo ese día. Pero lo apunto.
A veces la mejora más barata de un Proxmox no es comprar hardware. Es dejar de regalar recursos a máquinas que no los usan.
red: netin y netout como pista, no como métrica perfecta#
Estos dos campos son útiles para olfatear actividad.
| |
No los uso como monitorización de red seria. Para eso hay herramientas mejores. Pero sí me ayudan a distinguir una VM completamente dormida de una que ha movido algo desde que arrancó.
Si una VM está corriendo y tiene tráfico, sé que probablemente alguien o algo la está usando. Si está corriendo desde hace días con cero tráfico, puede ser normal o puede ser basura encendida.
Esa sospecha me ha ahorrado bastantes recursos. Hay máquinas que siguen levantadas porque nadie se acordó de apagarlas. No fallan, no hacen ruido, no mandan alertas. Solo consumen RAM y sitio en backups. netin y netout no lo demuestran todo, pero a veces te señalan el hilo.
lock es una palabra pequeña que cambia el plan#
En la captura aparece una VM con lock.
| |
Cuando veo eso, no fuerzo nada. Primero entiendo qué está pasando.
Un lock por backup puede ser normal si hay un vzdump en curso. También puede ser una marca que se quedó después de un trabajo fallido. La diferencia importa muchísimo. Si hay un backup vivo, tocar la VM a lo bruto es pedir problemas. Si el lock se quedó colgado, hay que limpiarlo con cuidado y sabiendo por qué quedó ahí.
Aquí cruzo con la lista de tareas recientes.
| |
Y si hace falta miro logs del backup. No me gusta borrar locks como quien quita una pegatina. A veces hay que hacerlo, pero prefiero llegar a esa decisión con contexto.
uptime: cuánto lleva viva una VM#
El uptime de una VM me da contexto.
| |
Una VM que lleva muchos días encendida y está estable probablemente no necesita mi atención inmediata. Una VM que esperaba ver apagada y lleva cinco días viva sí me hace levantar una ceja.
También sirve después de una incidencia. Si alguien dice “esa VM no se ha reiniciado” y el uptime dice otra cosa, ya tenemos conversación. No con drama, con datos.
El uptime no te dice si la aplicación dentro está sana. Puede haber una VM perfectamente encendida con un servicio roto dentro. Pero para saber si la máquina se ha reiniciado, arrancado o parado hace poco, ayuda.
tags: útiles, pero cuidado con meter secretos#
Las etiquetas son comodísimas para ordenar VMs, pero hay que tener un mínimo de higiene.
| |
Yo intento que las tags digan función, criticidad o grupo. core, lab, backup, media, test, cosas así. Lo que no metería jamás en una tag es una IP real, un dominio privado, un nombre de cliente o una pista sensible.
Parece obvio, pero en homelab acabamos usando cualquier campo visible como bloc de notas. Luego haces una captura para documentar algo y ahí está la etiqueta enseñando más de lo que debería.
Para publicar capturas, saneo tags siempre. Para trabajar en casa, también intento que sean aburridas. Lo aburrido protege.
cómo lo uso en una rutina real#
Cuando quiero revisar un nodo, suelo hacer una pasada corta.
Primero saco la lista.
| |
Después miro solo las VMs running. Anoto cuáles son cargas reales y cuáles parecen pruebas olvidadas.
Luego reviso VMs apagadas con mucho disco o mucha RAM asignada. No porque estén causando presión ahora, sino porque ensucian el nodo y los backups.
Si veo locks, paro y cruzo con tareas.
Si veo una VM importante, miro configuración.
| |
Y si voy a tocar el nodo entero, combino esta lista con estado del nodo, HA y storage. qemu me dice qué máquinas hay. No me dice si el cluster está preparado para aguantar mis ganas de tocar cosas.
lo que este comando no te cuenta#
No te dice si el sistema operativo dentro de la VM está bien. Puede reportar running y tener el servicio principal muerto.
No te dice si la aplicación responde. Para eso necesitas checks externos, logs internos o monitorización.
No te dice si el disco virtual tiene snapshots raros, backups buenos o configuración sensata. Para eso hay que mirar más.
Tampoco te dice si mover esa VM a otro nodo es buena idea. Necesitas saber storage, red, HA y recursos del destino.
Pero como inventario rápido de un nodo, me parece excelente. Es el tipo de comando que no impresiona a nadie y aun así evita errores tontos. Y en Proxmox los errores tontos son los que más rabia dan, porque casi siempre eran evitables con treinta segundos de lectura.
mi lectura rápida#
Si tengo que decidir en menos de un minuto, leo así.
Primero busco VMs running. Eso define qué carga vive en el nodo.
Después miro locks. Si hay uno, no toco esa VM sin revisar tareas.
Luego miro RAM máxima y CPUs asignadas. Quiero entender cuánto margen real tengo si cambian las cosas.
Después miro nombres, VMIDs y tags para saber qué es producción casera, qué es prueba y qué debería limpiarse.
Por último miro uptime y tráfico de red para separar máquinas vivas de máquinas olvidadas.
No es una auditoría completa. Es una forma de no entrar a ciegas. Para mí, pvesh get /nodes/<nodo>/qemu se ha convertido en una de esas comprobaciones pequeñas que haces antes de tocar nada serio. No arregla el nodo. Te quita una mala decisión de encima, que ya es bastante.