Los contenedores LXC son una de las mejores trampas del homelab. Son ligeros, arrancan rápido, consumen poco y por eso mismo acabas creando más de los que deberías. Un proxy temporal. Un DNS de prueba. Un contenedor para una herramienta que querías mirar media hora. Otro para un servicio que al final no usas, pero que sigue ahí porque no molesta.
Hasta que molesta.
Cuando quiero ver qué contenedores viven en un nodo Proxmox, uso esto.
| |
Es la versión LXC de la lista rápida. Estado, memoria, swap, disco, red, tags, uptime y VMID. No sustituye a pct config, pero me da el mapa inicial. Y muchas veces el mapa inicial ya enseña dónde está el barro.
la captura real de este post#
La captura sale de un nodo real. He saneado nombres, etiquetas y cualquier pista interna. Mantengo la estructura porque eso es lo útil.
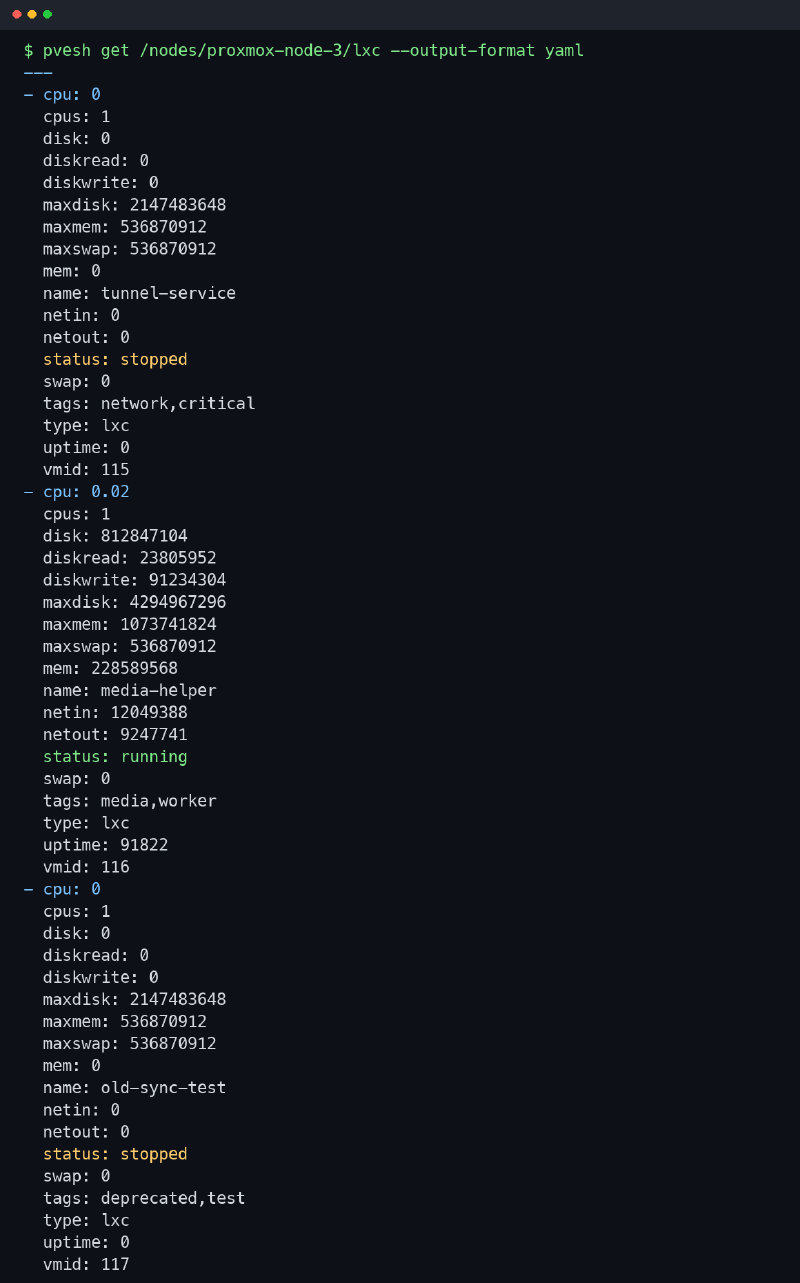
En este ejemplo se ven contenedores apagados y uno encendido. También aparecen límites de memoria, swap, disco y tags. Es una salida pequeña, pero suficiente para explicar cómo leo estos contenedores antes de empezar a tocar servicios.
por qué LXC necesita una revisión distinta a las VMs#
Una VM pesa mentalmente. La creas con más respeto. Le das disco, RAM, ISO, cloud-init si toca, red y tiempo. Un contenedor LXC se crea con demasiada facilidad. Esa es su virtud y su peligro.
En mi laboratorio, los LXC suelen alojar servicios pequeños. Un túnel, una herramienta de mantenimiento, un worker, un servicio auxiliar, alguna prueba de red. Cosas que no justifican una VM completa pero que tampoco quiero mezclar dentro de un Docker host gigantesco.
El problema es que esa comodidad anima al desorden. Si no revisas de vez en cuando, acabas con contenedores apagados que nadie recuerda, contenedores encendidos con 512 MB que se quedan cortos, tags llenas de notas malas y discos pequeños que un log puede llenar en una semana tonta.
Por eso me gusta tener este comando en la mano.
status: encendido no significa sano#
La primera línea que busco es la misma que con las VMs.
| |
O esta.
| |
Un LXC running solo significa que el contenedor está arrancado. No significa que el servicio dentro responda. No significa que systemd esté feliz. No significa que el puerto esté abierto. Y desde luego no significa que el servicio esté haciendo algo útil.
Pero es el primer filtro.
Si un contenedor crítico está parado, ya tengo una pista. Si un contenedor que yo creía retirado está encendido, también. Si todos los contenedores aparecen apagados y aun así el nodo tiene carga, sé que tengo que mirar VMs, procesos del host o storage.
Lo importante es no pedirle a status más de lo que da. Es un semáforo de contenedor, no un chequeo de aplicación.
memoria y swap: los límites pequeños también muerden#
En LXC miro bastante estos campos.
| |
Los contenedores pequeños suelen vivir con límites pequeños. 512 MB aquí, 1 GB allá. La mayoría del tiempo va bien. Hasta que actualizas, el servicio crece, un proceso se queda tonto o una tarea puntual necesita más memoria.
Con VMs tiendo a pensar en bloques grandes de RAM. Con LXC pienso en límites estrechos. Un contenedor puede funcionar meses con 512 MB y luego caerse en una actualización porque durante diez segundos necesitaba algo más.
Por eso no miro solo mem. Miro maxmem. Si mem está cerca del límite, no espero a que falle. Reviso dentro o subo margen si el servicio merece seguir vivo.
La swap también cuenta. Si un contenedor empieza a tirar de swap con frecuencia, puede seguir funcionando, pero quizá se vuelva lento de una forma muy desagradable. Peor aún, puede parecer que el servicio externo va mal cuando en realidad está ahogado en un límite que puse yo una noche cualquiera.
disco: dos gigas parecen mucho hasta que hay logs#
Los LXC pequeños suelen tener discos pequeños.
| |
Dos gigas pueden bastar para un servicio diminuto. También pueden llenarse con logs, cachés, descargas temporales o una actualización que no limpió bien. No hace falta que el contenedor sea grande para romperse por disco lleno.
La salida de pvesh me da una primera pista con disk y maxdisk. Si veo un contenedor encendido con disco muy justo, lo siguiente es entrar y mirar.
| |
Luego dentro hago lo de siempre.
| |
No hay glamour. Hay espacio libre o no lo hay.
Una cosa que aprendí a base de sustos menores es que los contenedores auxiliares rara vez avisan antes de llenarse. Un proxy, un túnel o una herramienta de sincronización pueden dejar de funcionar por una causa aburridísima. Disco lleno. La avería más poco épica del mundo.
red: tráfico bajo no significa servicio inútil#
netin y netout ayudan, pero hay que leerlos con cuidado.
| |
Un contenedor con poco tráfico puede estar muerto. O puede ser un servicio que solo responde de vez en cuando. Un DNS local puede parecer tranquilo hasta que lo necesitas. Un túnel puede mover poco tráfico pero ser crítico para publicar una web. Un monitor puede estar callado porque todo va bien.
Uso la red como pista, no como sentencia.
Si un contenedor lleva semanas encendido, con casi nada de tráfico y sin tags claras, sospecho. Si tiene una tag critical o network, me lo tomo con más calma y reviso antes de apagar nada.
Aquí es donde tener buenas tags ayuda mucho. No para que el panel quede bonito, sino para no cargarte algo importante por verlo aburrido.
tags: útiles si no las conviertes en vertedero#
En LXC las tags se vuelven tentadoras. Como muchos contenedores son pequeños, acabas usándolas para recordar función, red, criticidad o estado.
| |
Eso me parece bien. Lo que no me parece bien es meter direcciones reales, dominios privados, nombres de clientes o notas largas. Las tags aparecen en capturas, en la API y en salidas de terminal. Si las usas como libreta privada, tarde o temprano enseñarás algo que no querías.
Mi preferencia es usar etiquetas cortas y aburridas. network, media, monitoring, test, critical, deprecated. Con eso basta.
Si necesito documentar más, lo pongo en una nota interna, no en la tag del contenedor.
type: lxc parece redundante, pero ayuda al leer salidas mezcladas#
En la salida aparece esto.
| |
Sí, estamos consultando /lxc, así que parece obvio. Pero cuando copias salidas, las pegas en notas o las juntas con inventarios de VMs, ese campo ayuda. Proxmox maneja muchas cosas por VMID y es fácil mezclar mentalmente una VM QEMU con un contenedor LXC si solo miras nombres.
Yo intento no tratarlos igual.
Para una VM uso qm.
| |
Para un LXC uso pct.
| |
Parece básico, pero cuando estás cansado y vas rápido, lo básico evita meteduras de pata.
cuándo uso esta lista#
Uso pvesh get /nodes/<nodo>/lxc en varios momentos.
Antes de reiniciar un nodo, para saber qué contenedores se van a caer.
Antes de limpiar un laboratorio, para separar contenedores útiles de pruebas olvidadas.
Después de una incidencia de red, para ver si algún contenedor auxiliar estaba parado.
Antes de revisar backups, para saber qué contenedores deberían estar incluidos.
Cuando un nodo parece cargado, para comprobar si la presión viene de LXC o tengo que mirar hacia otro lado.
No siempre profundizo. Muchas veces solo necesito confirmar que lo que recordaba coincide con lo que existe. Y muchas veces no coincide, que es precisamente el motivo de usar comandos y no memoria.
cómo cruzo esta salida con pct#
pvesh me da la lista. pct me da el detalle operativo.
Si veo un contenedor sospechoso, miro configuración.
| |
Ahí ya reviso rootfs, red, features, montaje de recursos, DNS, si arranca al boot y cualquier opción rara. Si está encendido y quiero mirar dentro, entro.
| |
Si no quiero entrar, puedo ejecutar un comando puntual.
| |
Esto me gusta para contenedores de servicios pequeños. No necesito abrir una sesión larga. Pregunto algo concreto y salgo.
cuidado con apagar contenedores “pequeños”#
Hay un sesgo peligroso con LXC. Como pesan poco, parecen menos importantes.
No siempre lo son.
Un contenedor pequeño puede llevar un túnel, DNS, monitorización, un proxy, un job de backup o una pieza auxiliar que hace que otra cosa funcione. Apagarlo porque “solo consume 512 MB” puede romper una cadena que no tenías en la cabeza.
Por eso miro tags, red, uptime y nombre antes de tocar. Y si no está claro, reviso configuración y tareas recientes.
| |
Si el contenedor se arrancó hace poco por una automatización o falló en un backup, quiero saberlo antes de decidir.
mi rutina de limpieza#
Cuando hago limpieza de LXC, sigo una rutina bastante simple.
Primero saco la lista del nodo.
| |
Después marco mentalmente tres grupos.
Contenedores críticos que deben quedarse.
Contenedores de prueba que puedo apagar o borrar después de revisar.
Contenedores dudosos que necesitan mirar configuración o documentación.
No borro directamente desde una corazonada. Primero paro si está encendido, espero, compruebo que nada se queja y luego decido. Si es algo importante, backup antes. Borrar rápido da una sensación absurda de productividad hasta que te falta justo ese contenedor dentro de dos semanas.
lo que este comando no resuelve#
No te dice si el servicio dentro del contenedor responde. Para eso necesitas systemctl, logs o una comprobación externa.
No te enseña todos los detalles de red. Para eso miro pct config.
No te dice si el contenedor está bien respaldado. Hay que revisar jobs de backup y logs.
No te dice si el límite de memoria es correcto para el servicio. Solo te da números para empezar.
Y no te dice si un contenedor debería existir. Esa parte sigue siendo criterio humano, por desgracia. Sería cómodo que Proxmox tuviera una columna llamada “esto lo creaste a las dos de la mañana y ya no sirve”, pero todavía no hemos llegado ahí.
mi lectura rápida#
En menos de un minuto leo así.
Primero miro status. Quiero saber qué está vivo.
Luego miro maxmem, mem, maxswap y swap. Busco contenedores apretados.
Después miro disk y maxdisk. Un disco pequeño lleno puede explicar problemas muy raros.
Luego miro tags. Si algo dice critical, no lo trato como basura aunque parezca aburrido.
Por último miro uptime y red para detectar contenedores olvidados.
pvesh get /nodes/<nodo>/lxc no es espectacular. No pretende serlo. Es una lista seca de contenedores. Pero esa lista, leída con un poco de mala leche y memoria de sustos anteriores, evita tocar a ciegas. Y en un homelab con demasiadas piezas pequeñas, eso vale más que otra dashboard bonita.