Hay días en los que la interfaz web de Proxmox me parece demasiado educada.
Carga. Responde. Todo sigue más o menos en su sitio. Los nodos aparecen. Las VMs no se han caído. Y sin embargo noto esa sensación fea de que la foto está demasiado limpia para lo que ha pasado hace cinco minutos. Igual ha habido un reinicio raro. Igual una migración tardó más de la cuenta. Igual un nodo respondió lento y no me apetece fiarme solo de lo bonita que venga la web hoy.
En esos momentos me gusta bajar un escalón y mirar algo más seco. Algo con menos maquillaje. Ahí entra pvesh get /cluster/status.
No es el comando más famoso de Proxmox. Mucha gente vive perfectamente con pvecm status, la interfaz y poco más. Yo también uso pvecm status, de hecho me encanta, y ya conté por qué en pvecm status en Proxmox: cómo leo quorum, votes y ring ID antes de tocar un nodo. Pero pvesh get /cluster/status tiene un punto que me resulta especialmente útil. Me da una vista cruda del cluster desde la propia capa API de Proxmox. Sin adornos. Sin widgets. Sin tener que abrir navegador si estoy ya en terminal.
Y eso, cuando quiero una respuesta rápida a la pregunta “el cluster sigue entero o solo lo parece”, vale bastante.
por qué me gusta tanto este comando#
Porque junta en una sola tabla varias piezas que suelo querer ver antes de tocar nada.
- el nombre del cluster
- si Proxmox lo considera quorate
- cuántos nodos espera ver
- qué nodos salen online
- cuál es el nodo local
- qué IP de cluster está asociada a cada miembro
- la versión de la configuración del cluster
No parece una barbaridad. Y en realidad no lo es. Esa es la gracia.
No me obliga a interpretar veinte líneas de texto libre. No me pide acordarme de qué parte del panel estaba escondida. No me vende una sensación de estabilidad que todavía no he comprobado. Me pone la estructura delante y me deja leerla.
Además tiene otra virtud muy práctica. Si alguna vez quieres automatizar comprobaciones de estado o sacar datos para un script, ya estás usando la misma puerta que usa Proxmox por debajo. pvesh no deja de ser una forma cómoda de consultar la API local desde shell. Eso lo hace menos vistoso y más útil.
Buscando material para este artículo me encontré con lo esperable. En español hay poquísimo escrito sobre este comando concreto. Lo que aparece suele ser un hilo suelto, una respuesta en un foro o scripts que lo usan como pieza interna. Justo por eso me apetecía escribir esta guía. No porque sea un comando mágico, sino porque está infravalorado.
una salida real saneada que me parece muy honesta#
He preparado esta captura a partir de una salida real de mi cluster, saneada en nombres internos e IPs para no publicar datos privados que no aportan nada.
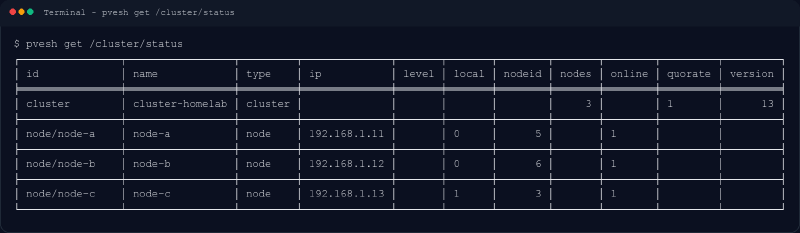
Lo que me gusta de esta salida es que no intenta impresionarte. Es simplemente una tabla con la foto básica del cluster.
- una fila de tipo
cluster - tres filas de tipo
node quoratea1- tres nodos visibles
- los tres online
- uno marcado como local
Parece poca cosa. Para mí no lo es. En una revisión rápida, esta tabla ya me contesta varias preguntas útiles sin abrir nada más.
la fila que manda de verdad es la del cluster#
Cuando lanzo el comando, no empiezo leyendo nodos. Empiezo leyendo la fila del cluster.
Es la que tiene id igual a cluster y la que trae varios campos que en las filas de nodo no aparecen o no significan nada.
name#
Aquí solo espero coherencia. Si administras un único cluster, esta parte es casi decorativa. Si tocas varios entornos o vienes de una tarde con demasiado café, confirmar el nombre nunca sobra. Parece una tontería hasta que un día te equivocas de contexto y empiezas a revisar el sitio que no era.
nodes#
Esta cifra me gusta porque aterriza la expectativa. Si el cluster debería tener tres nodos, aquí quiero ver tres. Si veo menos, ya sé que la revisión no va a ser una simple comprobación rutinaria.
La diferencia con mirar una lista en la web es pequeña, sí. Pero en terminal yo agradezco mucho que la expectativa y la realidad aparezcan en la misma línea.
quorate#
Aquí está una de las claves del comando.
En la fila del cluster, quorate: 1 es buena señal. Significa que el cluster tiene quorum desde el punto de vista de Proxmox y Corosync. No significa que todo lo demás esté perfecto. No me dice nada sobre Ceph, sobre la carga de las VMs o sobre si una migración concreta va a ir fina. Pero sí me dice que la base del cluster sigue en pie.
Cuando quiero un sí o no rápido antes de reiniciar un nodo, mover una VM o tocar algo pequeño, esta columna me ahorra bastantes rodeos.
Dicho eso, no la trato como diagnóstico final. Si algo me huele mal, después salto a pvecm status porque ahí tengo más contexto sobre votos, quorum y ring ID. Pero para un vistazo inicial, ver este 1 me da tranquilidad.
version#
Esta columna suele pasar desapercibida y a mí me parece más útil de lo que parece. La versión de configuración del cluster no es una métrica de salud, pero sí me ayuda a detectar si ha habido cambios recientes en la configuración distribuida.
Si todo venía estable y de repente algo raro coincide con un salto de versión, ya tengo un hilo del que tirar. No siempre significará problema. A veces solo habrá habido un cambio previsto. Pero es contexto. Y el contexto en clusters siempre paga.
luego sí, miro las filas de nodo#
Después bajo a las filas node/....
Aquí lo que busco es algo muy sencillo. Que el mapa me cuadre.
name#
Quiero ver todos los nodos que espero ver, con nombres reconocibles y sin sorpresas. Si uno falta, ya tengo la primera alerta. Si uno aparece con un nombre que no me cuadra, me paro. No suele pasar, pero el día que pasa te alegras de haber mirado.
ip#
Esta columna tiene más valor del que le damos cuando todo va bien.
No solo me recuerda qué IP está asociada a cada miembro del cluster. También me sirve para cruzar mentalmente si la red que estoy tocando o revisando es la correcta. En laboratorios con varias interfaces, VLANs o cambios recientes de red, esta columna evita bastantes tonterías.
En mi caso no la uso para memorizar nada, para eso ya tengo notas y documentación. La uso para detectar incoherencias. Si el nodo sale con una IP que no es la que debería usar para el cluster, la terminal ya me está avisando de que toca mirar más abajo.
local#
Me gusta mucho este campo porque elimina una duda absurda pero frecuente cuando entras por SSH saltando de un nodo a otro. local: 1 te deja claro desde qué miembro estás leyendo la foto.
Parece obvio, sí, pero cuando llevas varias terminales abiertas y has rebotado entre hosts, un recordatorio seco y visible de cuál es el nodo local se agradece.
Además me ayuda a interpretar el resto. No es lo mismo ver un nodo remoto caído desde un miembro sano que leer la salida desde el propio nodo que sospechas que está raro.
online#
Esta es la columna que más rendimiento me da por segundo.
Si veo online: 1 en los nodos que espero, ya sé que la API del cluster los sigue viendo vivos. Ojo con esto. No es una promesa eterna. No me dice que cada servicio del nodo esté perfecto ni que el storage vaya bien. Pero sí me ahorra una visita inútil a la web solo para confirmar si el miembro sigue dentro de la conversación.
Cuando un nodo sale con online: 0, la lectura cambia muchísimo. Ya no estoy comprobando una sensación. Ya tengo una ausencia clara en la tabla.
por qué esta vista me parece tan útil cuando la interfaz va lenta#
Hay un momento muy concreto en el que uso este comando muchísimo. Cuando la web sigue funcionando, pero va con esa lentitud sospechosa que no llega a ser caída.
La UI puede tardar en refrescar, puede arrastrar estado un rato o puede obligarte a navegar por varias pantallas para responder una pregunta bastante simple. pvesh get /cluster/status evita todo eso.
Entro por SSH en cualquier nodo del cluster, lo lanzo y en segundos tengo una foto básica. Si la tabla sale coherente, sigo con otra comprobación. Si no sale coherente, ya sé que no tiene sentido perder tiempo en paneles.
Ese uso tan mundano es justo el que más valoro. No me resuelve la avería, pero me coloca rápido en el carril correcto.
me gusta porque es más API que narración#
Otra razón por la que le tengo cariño a este comando es que se lleva muy bien con automatización y con comprobaciones repetibles.
Si lo quiero leer yo, la salida tabular me vale. Si quiero trabajarlo con scripts, puedo pedir JSON o YAML y listo.
Por ejemplo:
| |
O esta otra, que también uso cuando quiero algo legible sin pelearme con una tabla muy ancha:
| |
Aquí es donde me parece que pvesh tiene un punto bastante elegante, aunque la palabra elegante quizá le quede grande a una herramienta tan seca. Empiezo con la vista humana y si necesito rascar más, sigo con formatos de salida que un script digiere sin drama.
Para checks de cron, paneles pequeños o verificaciones antes de mantenimiento, eso es una delicia. Y no hace falta montar nada raro.
cuándo prefiero esto frente a pvecm status#
No es una competición. Uso ambos. Pero no para exactamente lo mismo.
pvecm status me gusta cuando quiero entender el quorum con más contexto. Votos esperados, votos presentes, ring ID, proveedor de quorum. Ahí sigue siendo rey.
pvesh get /cluster/status me gusta cuando quiero una foto compacta del cluster tal y como la expone Proxmox a través de su API local. Es más estructurado. Más fácil de parsear. Más cómodo para cruzar nodos, IPs y estado online de un vistazo.
Si tengo que resumirlo muy corto, diría esto.
pvesh get /cluster/statuspara ver el mapapvecm statuspara entender el suelo que pisa ese mapa
Cuando los uso juntos, tardo menos en orientarme y cometo menos suposiciones tontas.
también me sirve para detectar cuándo no debo confiarme#
Esta tabla es muy buena dando tranquilidad rápida. Y también es bastante buena fastidiando la confianza cuando toca.
Hay varias cosas que me harían parar.
- el cluster aparece con menos nodos de los esperados
quorateno sale a1- un nodo clave viene con
online: 0 - la IP de un miembro no cuadra con la red que debería estar usando
- la versión de configuración me sugiere que hubo cambios recientes que yo no tenía presentes
Nada de eso te da todavía la causa exacta. Pero te dice algo importante. No estás en una revisión de rutina. Estás en una situación que merece más cariño antes de tocar nada.
Y a veces eso es justo lo que necesito que me diga un comando. No la novela completa. Solo si toca seguir o frenar.
lo que no me cuenta, para no pedirle milagros#
Aquí conviene no fliparse.
pvesh get /cluster/status no me dice por qué un nodo está mal. No me confirma que Corosync esté fino a nivel de enlace. No me habla del estado de Ceph. No me cuenta si HA está cómoda o con el cuchillo entre los dientes. Tampoco me va a explicar una latencia rara en almacenamiento o una migración que se está arrastrando.
Su trabajo es otro. Darme una foto cruda de la estructura del cluster que Proxmox cree estar viendo en ese instante.
Y eso, sinceramente, ya es bastante.
Si necesito más, salto a otras piezas.
pvecm statuspara quorum con detallecorosync-cfgtool -spara mirar el enlace local de Corosyncsystemctl status corosyncpara ver el servicio en el nodoha-manager statussi estoy tocando nodos que cargan servicios en HAceph -ssi el storage compartido entra en la ecuación
Cada comando tiene su sitio. El error es pedirle a uno que sustituya a todos.
mi rutina corta cuando algo no me termina de convencer#
Cuando noto que el cluster está raro, esta suele ser mi secuencia.
pvesh get /cluster/statuspvecm statuspvecm nodescorosync-cfgtool -s- si hay storage compartido,
ceph -s
Ese orden no tiene nada de sagrado, pero me funciona muy bien. Empiezo por una tabla que me da el mapa. Paso luego a quorum más detallado. Confirmo miembros. Bajo al enlace local de Corosync. Y solo después sigo con storage o con la parte específica que huela peor.
El resultado práctico es que pierdo menos tiempo en la interfaz y menos tiempo también en historias inventadas. El cluster normalmente ya me ha dicho bastante en los dos primeros minutos.
dónde le saco más partido de verdad#
No en los desastres grandes. Ahí casi cualquier comando te canta que algo serio va mal.
Donde más valor le saco es en los días grises.
Un nodo respondió lento después de un backup. Hubo una reconexión rara. La interfaz tardó demasiado en refrescar. Quiero reiniciar uno de los hosts, pero antes necesito saber si el cluster viene estable o viene sosteniéndose con cara de póker. En esas situaciones pvesh get /cluster/status es una herramienta cojonuda.
Me da una respuesta rápida sin obligarme a leer demasiada narrativa. Y cuando administras un homelab con varios nodos, eso se agradece muchísimo.
mi conclusión#
pvesh get /cluster/status no es el comando más famoso de Proxmox, pero a mí me parece de los más rentables cuando quiero una foto rápida y estructurada del cluster. Me enseña el mapa. Me dice si el cluster sale quorate. Me deja ver nodos, estado online, nodo local e IPs sin depender de la web.
No sustituye a pvecm status. No sustituye a Corosync. No sustituye a Ceph. Pero sí me ayuda a decidir si estoy en una situación normal o si mejor bajo el ritmo antes de tocar nada.
Si administras Proxmox y todavía no lo tienes en tu rutina, yo lo probaría. No por moda. Porque cuando la interfaz parece demasiado tranquila, una vista más cruda suele decir la verdad antes.
referencias#
- Documentación oficial de Proxmox VE sobre Cluster Manager
- API viewer de Proxmox VE
- Post relacionado: pvecm status en Proxmox: cómo leo quorum, votes y ring ID antes de tocar un nodo
- Post relacionado: pvecm nodes en Proxmox: la comprobación corta que hago para confirmar quién sigue dentro del cluster
- Post relacionado: Cómo reviso la salud de un cluster Proxmox en dos minutos antes de tocar nada