Hay comandos que uso para diagnosticar un problema. Y luego hay comandos que uso para no perder el tiempo antes de que el problema exista de verdad.
pvesh get /cluster/resources --type node pertenece clarísimamente al segundo grupo.
No es el más famoso de Proxmox. No tiene el aura de pvecm status, que sigue siendo el rey cuando quiero hablar de quorum. Tampoco tiene el punto bruto de pveperf, que ya conté en pveperf en Proxmox: la prueba rápida que hago para leer CPU, disco y fsync antes de culpar al nodo. Pero este comando tiene una virtud muy concreta que me encanta. Me enseña la foto corta de todos los nodos a la vez.
Y esa foto corta, bien leída, vale mucho.
Hay mañanas en las que no necesito una autopsia. Solo necesito saber si estoy a punto de reiniciar el host más cargado del cluster como un animal, si uno de los nodos viene recién arrancado, si otro va más apretado de RAM de lo normal o si todo sigue razonablemente en orden antes de tocar nada. Para eso esta tabla me parece cojonuda.
La gracia está en que no me obliga a saltar por la interfaz, ni a abrir el resumen de cada nodo, ni a fiarme de una intuición vaga tipo “creo que este iba más libre”. Me da una línea por nodo y me pone delante justo lo que suelo querer ver primero.
qué hace exactamente este comando#
La propia ayuda de pvesh lo deja bastante claro. /cluster/resources es un índice de recursos a nivel de cluster. Con --type node, le estás pidiendo solo la parte de nodos.
Dicho en castellano normal, Proxmox te devuelve una tabla donde cada fila es un host del cluster y cada columna te resume parte de su estado.
Eso suele incluir cosas como estas.
- identificador del nodo
- estado
- uso de CPU
- memoria usada
- memoria total
- disco usado
- uptime
- número de CPUs disponibles
Lo bonito es que no hay que rascar mucho para empezar a sacar conclusiones útiles.
la captura que me gusta tener delante#
He preparado esta captura a partir de una salida real de mi lab, saneada en nombres internos para no publicar hostnames que no aportan nada.
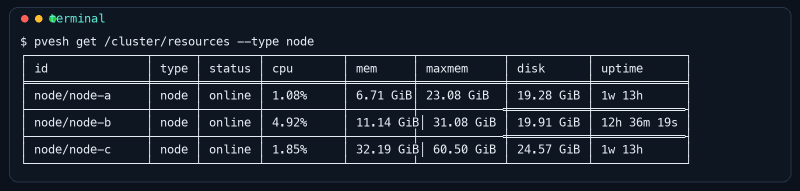
No es una tabla perfecta. De hecho me gusta precisamente porque no intenta serlo. Es seca, bastante fea y muy útil.
En un vistazo ya veo tres cosas.
- los tres nodos están online
- uno viene con bastante más memoria ocupada que los otros
- uno lleva menos uptime y por tanto seguramente ha reiniciado hace menos
Eso ya me cambia cómo entro al cluster. Y lo hace antes de abrir una sola pantalla de la web.
por qué me gusta más de lo que parece#
Porque me evita un fallo muy humano. Pensar en nodos en abstracto.
En cuanto un cluster crece un poco, aunque solo sean tres nodos en casa, cada host va cogiendo personalidad. Uno acaba tragándose más VMs gordas. Otro se queda con más LXCs. Otro lo tocas más a menudo por pruebas. Otro reinicia más veces porque es el laboratorio del laboratorio. Si no miras una tabla global antes de actuar, es muy fácil tomar decisiones con una foto mental que ya va vieja.
A mí me pasa. Y justo por eso me apoyo tanto en este comando.
No me dice todo, pero me obliga a arrancar desde datos en vez de recuerdos.
cómo leo cada columna sin ponerme dramático#
No hace falta interpretar hasta el último decimal. Yo lo uso con una lectura muy práctica.
id#
Aquí solo quiero identificar rápido cada nodo. Normalmente viene como node/<nombre>. No tiene misterio, pero sí tiene valor. Me ayuda a no confundirme cuando salto entre hosts o cuando estoy en una sesión SSH y quiero confirmar qué miembro del cluster estoy mirando en cada momento.
En la captura salen node-a, node-b y node-c porque he saneado los nombres. En un entorno real verás los tuyos.
status#
Si aquí no veo online, la conversación ya cambia.
Parece una obviedad, sí. Pero una obviedad útil. Hay días en los que la interfaz responde, el cluster no parece roto y sin embargo hay un nodo raro, recién vuelto, parcialmente aislado o directamente desaparecido. Esta columna me deja ver de inmediato si Proxmox considera al nodo presente en la foto global.
No reemplaza a pvesh get /cluster/status en Proxmox: la vista cruda que miro cuando la interfaz parece demasiado tranquila, pero se complementa de maravilla con ese comando.
cpu#
No miro la CPU para asustarme. La miro para orientarme.
Si un nodo sale al 1 por ciento y otro al 35 por ciento, ya sé que no es el mejor momento para reiniciar el segundo a ciegas, ni para tirarle encima una migración pesada sin pensar. En la mayoría de homelabs la CPU se mueve mucho y una cifra aislada no cuenta toda la historia, pero como termómetro instantáneo funciona sorprendentemente bien.
También me ayuda a detectar una sensación rara bastante común. Cuando un host no va saturado de RAM ni de disco, pero algo sigue oliendo a lento. Si el uso de CPU viene más alto de lo esperado, ya tengo una pista. Si viene bajo, miro otras capas.
mem y maxmem#
Esta pareja es probablemente la que más miro.
No porque la memoria lo explique todo, sino porque es la columna que más rápido me evita una cagada. A simple vista veo qué nodo va más cargado y cuánto margen queda antes de meter mano.
En la captura, node-c viene bastante más lleno que los otros dos. Eso no significa automáticamente que esté mal. Puede ser el host más potente y el más cargado por diseño. Pero si yo tenía pensado reiniciar justo ese, parar VMs ahí o moverle otra carga encima, esta tabla ya me está diciendo “míralo dos veces”.
Me gusta mucho porque no necesito hacer cuentas mentales raras. Proxmox me pone usada y total en columnas separadas, con formato humano. Con eso me basta.
disk#
Aquí conviene recordar qué estás viendo. En el caso de los nodos, disk refleja uso del filesystem del host, no la película completa de todos tus storages del cluster.
Aun así me parece útil. Si un nodo viene bastante más lleno que los demás, eso influye en cómo interpreto el resto de síntomas. Sobre todo si estoy trabajando con logs, backups locales, imágenes temporales o un root que se va estrechando sin hacer demasiado ruido.
No sustituye a pvesm status en Proxmox: cómo leo el almacenamiento de verdad y qué señales no ignoro. Pero como pista rápida, suma mucho.
uptime#
Esta columna me encanta porque cuenta una historia en muy poco espacio.
Si dos nodos llevan una semana arriba y uno lleva doce horas, ya sé que algo pasó. Igual fue un reinicio previsto. Igual hubo mantenimiento. Igual ese host se cayó y volvió. Igual tocaste kernel, BIOS o red. En cualquier caso, el uptime mete contexto sin obligarte a abrir logs todavía.
Yo la uso muchísimo para no discutir con mi propia memoria. A veces juraría que un host llevaba días estable y la tabla me recuerda que no, que reinició ayer por la tarde.
Ese tipo de corrección humilde me parece valiosísima.
dónde encaja en mi rutina de verdad#
Este comando me resulta especialmente útil en cuatro momentos.
antes de reiniciar un nodo#
Este es el caso más claro.
Si voy a reiniciar por kernel, actualizaciones, BIOS o simple mantenimiento, quiero una lectura rápida de cómo llegan los tres hosts. No necesito todavía detalle fino. Necesito saber si hay uno más cargado que el resto, si alguno viene raro de uptime o si el cluster ya está más desequilibrado de lo que me gustaría.
Con esta tabla veo enseguida si estoy a punto de reiniciar el nodo menos conveniente.
antes de mover VMs o CTs por intuición#
Hay una frase peligrosa que todos nos hemos dicho alguna vez. “La paso al otro nodo, que creo que iba más libre”.
El problema es ese “creo”.
pvesh get /cluster/resources --type node me deja comprobar esa intuición en dos segundos. No es un algoritmo de placement mágico. No me calcula afinidad, NUMA ni impacto real de una carga concreta. Pero me da una base bastante mejor que la memoria difusa de ayer.
cuando la web va bien, pero no me fío del todo#
A veces la interfaz carga, pero no termina de transmitir paz. Todo parece más o menos correcto y sin embargo noto algo raro. En esos momentos me gusta bajar a terminal y sacar esta tabla.
Si la foto global de nodos es coherente, sigo con la siguiente capa. Si no lo es, ya sé que no merece la pena seguir navegando menús como si nada.
cuando quiero comprobar si el cluster está equilibrado o simplemente vivo#
Este comando no me responde si el cluster está bien diseñado. Eso depende de mucho más. Pero sí me responde algo muy práctico. ¿Cómo están repartidas ahora mismo la presión y la antigüedad de cada host?
No parece una gran pregunta hasta que llevas unas semanas tocando cosas y ya no recuerdas exactamente qué nodo estaba haciendo de mula.
lo que me gusta frente a otras opciones#
La interfaz web de Proxmox también me enseña CPU, memoria y disco por nodo. Claro. Pero casi siempre tardo más en montarme la foto completa. Voy de un panel a otro. Cambio de contexto. Abro resúmenes. Y cuando termino, ya he invertido más tiempo del que quería para una simple orientación.
Con esta tabla lo tengo todo junto.
Frente a pvecm status, la diferencia es otra. pvecm status me da contexto de quorum y cluster manager. Es mejor para entender el suelo político del cluster, por decirlo de alguna forma. Este comando me da una foto operativa de hosts.
Yo lo resumiría así.
pvecm statuspara entender el cluster como clusterpvesh get /cluster/resources --type nodepara entender el cluster como colección de máquinas que ahora mismo tienen una carga concreta
Las dos miradas me parecen necesarias.
un detalle que me gusta mucho, sale fácil en JSON#
Aquí pvesh vuelve a lucirse.
Si quiero una tabla rápida, la salida por defecto me vale. Si quiero jugar con el resultado en un script, un cron o un check más automatizado, puedo sacarlo en JSON sin pelearme mucho.
| |
Eso me gusta bastante porque evita tener dos mundos separados. El comando humano y el comando para automatización son el mismo. Solo cambia el formato.
Para un homelab esto es ideal. Hoy lo lees tú. Mañana lo parsea un script para avisarte si un nodo lleva menos de cierto uptime o si uno aparece offline.
lo que no le pido para no hacer el ridículo#
También tiene límites. Y conviene respetarlos.
Este comando no me dice por qué un nodo consume más memoria. No me explica si la CPU alta es por una VM concreta, por IO wait o por otra cosa. No me enseña latencia de storage, ni estado detallado de Ceph, ni salud de Corosync, ni servicios del host.
Tampoco hay que leerlo como si fuera un panel de observabilidad completo. Es una foto rápida. Muy buena. Muy útil. Pero rápida.
Si algo no cuadra, salto a otras piezas.
pvecm statuspara quorum y votospveperfpara lectura rápida de rendimiento localceph -ssi el almacenamiento compartido entra en la jugadasystemctl status pve-clustersi sospecho del filesystem de configuracióncorosync-cfgtool -ssi el problema huele a red de cluster
Cada herramienta tiene su sitio. Y ese orden mental me ahorra bastante tiempo.
una lectura práctica que me funciona muy bien#
Cuando saco esta tabla, no intento exprimirla entera. Hago una pasada de diez segundos.
Primero miro si todos están online.
Luego comparo memoria usada entre nodos.
Después miro el uptime para detectar quién es el recién llegado a la fiesta.
Y por último me fijo en CPU y disco, solo para ver si hay algún outlier que me obligue a bajar el ritmo.
Esa secuencia tan simple me funciona porque responde justo a la pregunta con la que suelo arrancar. “¿Estoy a punto de tocar el nodo correcto o me estoy montando una película?”
La mayoría de las veces, esa pregunta ya queda bastante contestada ahí.
también me ayuda a detectar desequilibrios que se vuelven invisibles#
Esto me parece importante.
Cuando tienes un cluster pequeño en casa, los desequilibrios se normalizan muy rápido. Uno de los nodos se convierte en el host que siempre lleva más cosas. Otro se queda de backup moral. Otro recibe pruebas. Y como el cluster sigue funcionando, te acostumbras.
Hasta que un día no.
Por eso me gusta tanto tener una tabla global tan accesible. Me devuelve la perspectiva. No me deja romantizar el supuesto equilibrio de un cluster que igual lleva semanas cargando más de la cuenta siempre sobre el mismo pobre cabrón.
No es una auditoría seria. Pero como bofetada amable de realidad, va estupenda.
mi conclusión#
pvesh get /cluster/resources --type node no es el comando más glamuroso de Proxmox, pero a mí me parece de los más rentables para la rutina real. Me enseña en una sola tabla qué nodos están online, cómo vienen de CPU, cuánta RAM están usando, cuánto root llevan ocupado y cuánto tiempo hace que arrancaron.
Eso no resuelve averías. Lo que hace es algo casi mejor. Evita que tomes decisiones tontas antes de provocarlas.
Si administras un cluster Proxmox y todavía no lo tienes a mano, yo le daría una oportunidad. No para sustituir a nada, sino para ganar una foto rápida de verdad antes de reiniciar, migrar o seguir confiando en recuerdos que ya van desfasados.
Y en homelab, donde media estabilidad consiste en no tocar el nodo equivocado en el peor momento posible, esa foto vale bastante.
referencias#
- Documentación oficial de pvesh
- Documentación oficial de Proxmox VE sobre Cluster Manager
- Post relacionado: pvesh get /cluster/status en Proxmox: la vista cruda que miro cuando la interfaz parece demasiado tranquila
- Post relacionado: pvecm nodes en Proxmox: la comprobación corta que hago para confirmar quién sigue dentro del cluster
- Post relacionado: pveperf en Proxmox: la prueba rápida que hago para leer CPU, disco y fsync antes de culpar al nodo