Hay comandos que no parecen gran cosa hasta que te ahorran media tarde de diagnósticos torpes. pveperf está en esa categoría.
No es bonito. No es moderno. No sirve para enseñar una captura impresionante en redes. Pero a mí me resulta muy útil porque me da en segundos una foto bastante honesta del nodo Proxmox antes de hacer dos cosas que salen caras cuando las haces mal. Actualizar confiado y culpar al cluster de algo que en realidad es culpa del host.
Yo no uso pveperf como benchmark para presumir de hardware. Lo uso como prueba de cordura. Quiero ver si CPU, lectura, seek, fsync y resolución DNS se parecen a lo que espero o si hay una cifra que ya me está diciendo “ojo, aquí algo no va tan fino como pensabas”.
Y me gusta por una razón muy simple. Me obliga a mirar el nodo como nodo, no solo como cajita donde viven VMs y contenedores.
por qué sigo lanzando pveperf aunque no sea una prueba perfecta#
Porque el mundo real del homelab no siempre necesita precisión quirúrgica. A veces lo que necesitas es una respuesta rápida a una pregunta bastante terrenal.
¿Este host tiene pinta de estar razonablemente sano o me está enseñando una rareza antes de que me meta en un update, una migración o un reinicio?
pveperf responde justo eso.
La documentación oficial de Proxmox deja además un detalle bastante práctico. No intenta venderlo como magia. Habla de bogomips, expresiones regulares por segundo, lecturas bufferizadas, seek medio, fsyncs y tiempos DNS, con umbrales orientativos. Ya con eso me vale. No necesito que el comando me prometa ciencia exacta. Me basta con que me sirva para detectar desviaciones llamativas.
En mi caso, lo lanzo sobre todo en cuatro momentos.
- antes de actualizar un nodo que lleva tiempo tranquilo
- cuando una VM empieza a ir rara y todavía no tengo claro si culpar a la propia VM o al host
- después de tocar storage o controladoras
- cuando quiero comparar rápido varios nodos del cluster sin montar una película de benchmarks
una salida real de tres nodos que me vino perfecta para este artículo#
He sacado la siguiente captura de tres nodos reales de mi cluster Proxmox. La he saneado en nombres internos y dominio local, pero los números son reales.
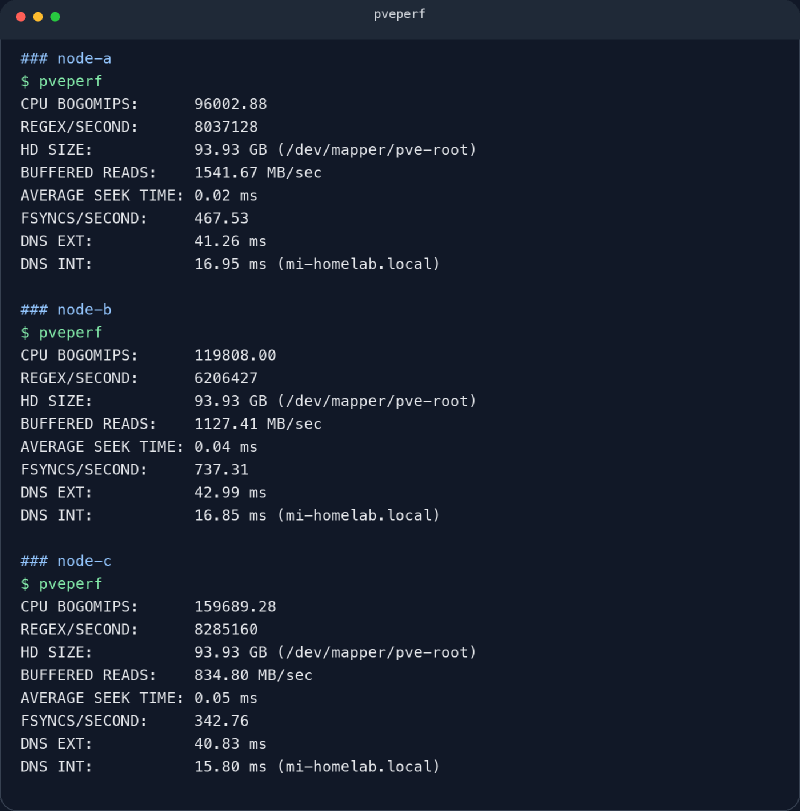
Lo bueno de esta salida es que resume muy bien cómo leo yo pveperf.
node-atiene buen read y un seek muy cortonode-bgana claramente en fsyncnode-ctiene la cifra de CPU más bestia, pero el peor fsync de los tres
Solo con eso ya saco una conclusión que me interesa bastante. La CPU más fuerte del grupo no garantiza el nodo más agradecido para todo. Si el camino de escritura y sincronización a disco no acompaña, el host puede ir sobrado de músculo bruto y aun así resultar menos cómodo para ciertas cargas.
Ese tipo de matiz es exactamente por lo que sigo usando pveperf.
qué miro primero al lanzar pveperf#
CPU BOGOMIPS#
No me obsesiona esta cifra, pero sí la leo.
Me sirve para detectar si el nodo está donde debería en potencia bruta y, sobre todo, si hay una anomalía rara frente a hosts parecidos. En la captura, node-c saca 159689.28, node-b se queda en 119808.00 y node-a en 96002.88.
Eso encaja bastante bien con una realidad muy típica del homelab. Un nodo puede ser claramente más bruto en CPU y seguir sin ser el mejor candidato para todo.
A mí esta parte me ayuda a no sacar conclusiones de barra de bar. Si el nodo tiene menos CPU de la que recordaba, ya no hablo igual de ciertas VMs. Si tiene mucha CPU pero luego falla por otra parte, sé que la conversación va por storage, sync o latencia, no por músculo bruto.
REGEX/SECOND#
Esta métrica me parece más curiosa que decisiva, pero aporta contexto.
No es la cifra que usaría para tomar una decisión gorda por sí sola. Aun así, cuando veo números muy descompensados entre nodos similares, me sirve como pista de que algo en la ejecución general del host merece una segunda mirada.
En la captura hay una cosa interesante. node-c lidera con 8285160, node-a va cerca con 8037128 y node-b baja a 6206427. No saco una conclusión dramática solo con eso. Pero sí me recuerda que un nodo puede rendir mejor o peor en tareas distintas y que la CPU no se resume bien con una única cifra.
BUFFERED READS#
Aquí ya empiezo a prestar mucha más atención.
La documentación de Proxmox habla de que discos modernos deberían pasar de 40 MB/s. Eso, hoy, es un umbral muy humilde. En SSD y NVMe domésticos o prosumer la conversación real está muchísimo más arriba. Por eso a mí no me interesa tanto aprobar el examen como comparar nodos y ver si alguno se cae del dibujo esperado.
En mi salida, node-a marca 1541.67 MB/sec, node-b 1127.41 MB/sec y node-c 834.80 MB/sec.
Las tres cifras son más que decentes para esta prueba rápida. Pero la diferencia existe y me interesa. Si un nodo con mucha CPU me da un buffered read bastante peor que otro más modesto, ya tengo un detalle para cruzar luego con tipo de disco, controladora, caché, carga real del host o simplemente con la ruta de almacenamiento elegida para ciertas VMs.
No necesito que el número sea malo para que me resulte útil. Me basta con que sea distinto.
AVERAGE SEEK TIME#
Esta cifra me gusta porque suele ser brutalmente clara.
0.02 ms, 0.04 ms, 0.05 ms en la captura. Aquí el mensaje es sencillo. Los tres nodos van rápidos y no huelen a cuello de botella grotesco en acceso aleatorio para esta prueba. Si aquí me apareciera una barbaridad respecto al resto, no seguiría con el mantenimiento sonriendo.
Además, el seek time me ayuda a poner los pies en el suelo cuando alguien se fija solo en la CPU. Puedes tener un nodo muy potente que luego arrastra un camino de disco peor resuelto. Y en virtualización eso se nota donde más fastidia, en la sensación de que todo “funciona” pero nada termina de ir fino.
FSYNCS/SECOND#
Para mí, esta es la parte más jugosa de pveperf.
La documentación oficial dice que el valor debería estar por encima de 200. En 2026, en un homelab que ya aspira a correr VMs con cierta alegría, yo no me quedo tranquilo solo porque supere 200. Quiero contexto y comparativa.
En la salida real de mis tres nodos, la foto es muy buena para explicar esto.
node-bsaca737.31node-ase queda en467.53node-cbaja a342.76
Y aquí está la gracia. node-c es el más bruto en CPU y, aun así, pierde claramente en fsync. Si yo mirara solo bogomips, podría asumir que es el nodo más cómodo para casi cualquier cosa. pveperf me recuerda que no.
Cuando trabajo con Proxmox, el fsync me importa mucho más de lo que muchos admiten en voz alta. Bases de datos, colas, servicios con escritura frecuente, incluso algunas VMs “ligeras” que luego hacen más sync del que parecía. Todo eso agradece un camino de escritura serio.
No estoy diciendo que con 342.76 el nodo esté roto. Ni de lejos. Estoy diciendo que, comparado con otro host del mismo cluster, ya tengo una pista clara de que la experiencia bajo ciertas cargas puede ser distinta.
Y esa pista me la da un comando que tarda nada.
la comparación que a mí más me interesa, CPU contra fsync#
Si tuviera que resumir el valor real de esta prueba en una sola idea, sería esta. pveperf me ayuda a no confundir potencia con equilibrio.
En homelab es muy fácil enamorarse del nodo más musculoso. Más cores, más frecuencia, más juguete nuevo. Luego resulta que el host más agradable para cierto tipo de VMs no es ese, sino el que tiene una ruta de almacenamiento mejor resuelta o una combinación más limpia entre CPU, disco y sincronización.
La captura de este artículo me parece perfecta para decirlo sin teoría barata.
- el nodo más flojo en bogomips no es el peor en almacenamiento
- el nodo intermedio en CPU gana en fsync
- el nodo más fuerte en CPU no lidera donde importa para escrituras sincronizadas
A mí esto me sirve para repartir mejor cargas y, sobre todo, para no echarle la culpa a Proxmox cuando el detalle real está en la personalidad del host.
los tiempos DNS también dicen más de lo que parece#
Mucha gente ignora DNS EXT y DNS INT. Yo no.
No porque crea que un par de milisegundos arriba o abajo vayan a decidir la vida del cluster, sino porque me gusta ver si el host resuelve fuera y dentro de casa de forma razonable.
En la captura, los tiempos externos rondan 40-43 ms y los internos 15-17 ms. No es una locura y, sobre todo, guardan coherencia entre nodos. Eso me gusta.
Si aquí viera un nodo disparado frente al resto, ya no seguiría tan tranquilo. Igual el problema no está en Proxmox. Igual está en un resolved raro, una ruta DNS torcida o un servicio interno que resuelve peor de lo que pensabas. Parece poca cosa, pero cuando un host empieza a comportarse raro, estos detalles ayudan a separar lo que es compute y storage de lo que es red o resolución.
lo que pveperf no es, para no pedirle tonterías#
Aquí conviene poner un poco de orden.
pveperf no es un benchmark serio de almacenamiento. No es fio. No es una batería controlada para comparar NVMe entre sí. No sirve para sacar conclusiones académicas ni para sentenciar cuál es el mejor nodo del planeta.
Tampoco me dice esto.
- cómo rendirá una VM concreta con su patrón real de IOPS
- cómo se comportará Ceph bajo una carga sostenida
- si una base de datos concreta va a ir bien o mal
- cómo afectará la caché del sistema a un test más largo
Pero eso no le quita valor. Al revés. Me gusta porque no intento convertirlo en algo que no es.
Su trabajo es otro. Darme una prueba corta, fea y muy rentable para detectar si el nodo ya canta antes de meterme en análisis más largos.
cómo lo uso yo antes de tocar un nodo#
Mi secuencia típica suele ser bastante simple.
pveperfpveversion -vpvecm statuspvesm statussi sospecho del storageha-manager statussi el host participa en HA de algo sensible
Ese orden no es casual. Quiero saber primero si el nodo me da una impresión sana en CPU, disco y sync. Luego reviso versiones y paquetes. Después miro cluster. Y solo después me pongo fino con HA o con el inventario de VMs.
Cuando hago esto al revés, acabo perdiendo tiempo en síntomas secundarios mientras el host ya me había dado una pista bastante clara al principio.
señales que me hacen frenar#
No hace falta que pveperf salga desastroso para que me haga parar un segundo. A mí me basta con cualquiera de estas situaciones.
un fsync claramente peor de lo esperado#
Si el nodo cae mucho respecto a hosts comparables, no me hago el valiente. Quiero saber por qué.
lecturas raramente bajas en un host que antes iba bien#
Aquí sospecho de disco, controladora, caché, saturación o incluso de un cambio que olvidé documentar. Y sí, eso pasa más de lo que me gustaría.
un nodo con mucha CPU pero sensación torpe en disco#
Esta combinación la he visto más veces de las deseables. Mucho hierro para presumir y luego una experiencia peor para ciertas cargas por detalles de storage.
tiempos DNS que se salen del dibujo del resto#
No es lo primero que miro, pero si un nodo resuelve peor que los demás, ya sé que la revisión tiene otra capa.
dónde me ha sido más rentable de verdad#
Curiosamente, no en los desastres. Ahí normalmente ya sabes que hay un problema y tiras de herramientas más serias. Donde más me compensa es en los días grises. Los días en que algo no termina de ir fino y todavía no tengo una teoría buena.
pveperf me ayuda a hacer una criba inicial muy rápida.
Si el host sale razonable, sigo mirando cluster, storage compartido, VM concreta o red. Si la prueba ya enseña una desviación clara, me quedo en el nodo y dejo de repartir culpas demasiado pronto.
Eso ahorra tiempo y, sobre todo, ahorra ruido mental. En homelab el ruido mental es peligrosísimo porque te lleva a hacer cambios antes de entender bien la foto.
mi conclusión#
pveperf no sustituye una prueba seria y no pretende hacerlo. Para mí vale precisamente porque es corto, feo y difícil de malinterpretar si lo usas con cabeza. Me enseña enseguida si CPU, lectura, seek, fsync y DNS están donde espero o si algún número ya me pide bajar el ritmo.
La captura real de mis tres nodos me parece una demostración estupenda de su utilidad. El nodo con más CPU no gana en fsync, el que parece más discreto lee mejor de lo esperado y el más equilibrado no es necesariamente el que más impresiona en bruto. Ese tipo de lectura me resulta mucho más útil que cualquier fantasía de benchmark heroico.
Si trabajas con Proxmox y quieres una comprobación rápida antes de actualizar, reiniciar o empezar a culpar al cluster, yo metería pveperf en la rutina sin pensarlo demasiado. No porque te vaya a responder a todo, sino porque te puede señalar el sitio correcto donde empezar a mirar.
Y en mantenimiento, empezar por el sitio correcto ya es media victoria.
referencias#
- Manual oficial de
pveperfen Proxmox VE - Documentación oficial de administración del host en Proxmox VE
- Post relacionado: pveversion -v en Proxmox: dónde veo paquetes raros antes de actualizar un cluster
- Post relacionado: pvesm status en Proxmox: cómo leo el almacenamiento de verdad y qué señales no ignoro
- Post relacionado: Cómo reviso la salud de un cluster Proxmox en dos minutos antes de tocar nada