Hay días en los que Proxmox te mira con cara de niño bueno. Todo verde, ninguna alarma fea, la interfaz carga rápido y uno empieza a pensar que quizá hoy sí puede tocar cosas sin pagar peaje. A mí ese momento me da exactamente la reacción contraria. Cuando un cluster parece demasiado tranquilo, me obligo a revisar lo básico antes de hacer nada que pueda mover piezas importantes.
Lo digo porque ya he aprendido que el desastre raro casi nunca empieza con una explosión cinematográfica. Empieza con una confianza tonta. Un reinicio que parecía inocente. Una actualización lanzada deprisa. Una VM que mueves de nodo porque sí. Dos minutos después estás preguntándote por qué HA no se comporta como esperabas o por qué Corosync decide ponerse estupendo justo hoy.
En mi caso, antes de tocar un cluster pequeño hago siempre el mismo chequeo corto. No es una liturgia sagrada ni una receta de manual. Es una rutina práctica que me sirve para responder una pregunta muy simple. ¿Está sano de verdad o solo parece sano desde lejos?
Y cuanto más pequeño es el cluster, más me importa esa diferencia. En una instalación doméstica de tres nodos no hay mucho margen para la épica. Si uno cae, otro está cargado y el tercero tiene algo a medias, la tontería te sale cara bastante rápido.
por qué no me fío solo del panel web#
La interfaz de Proxmox me gusta mucho. Lo digo en serio. Me parece de las pocas herramientas de infra que consiguen ser útiles sin ponerse demasiado intensitas. Pero no me basta para decidir si el cluster está listo para una operación delicada.
La razón es sencilla. El panel resume. Y a veces resumir demasiado te esconde justo el matiz que importa.
Yo quiero ver al menos estas capas antes de tocar nada.
- quorum real
- estado de HA
- inventario vivo de cargas
- almacenamiento con contexto
No porque sean las únicas cosas que importan, sino porque son las que más rápido me dicen si hoy toca trabajar o apartar las manos del teclado.
Si alguna de esas piezas ya viene rara, no sigo escalando complejidad. Primero entiendo la rareza. Después ya decidiré si actualizo, reinicio o simplemente cierro la sesión y me ahorro un problema elegante.
1. empiezo por quorum porque sin eso lo demás me da igual#
El primer comando que miro es pvecm status. Siempre.
No es el más bonito ni el que sale mejor en una demo, pero me da la fotografía que necesito del estado de cluster. Si el cluster no está quorate, ya puedo tener la UI muy simpática que no pienso tocar nada serio.
Esta es una salida saneada basada en una comprobación real de esta madrugada.
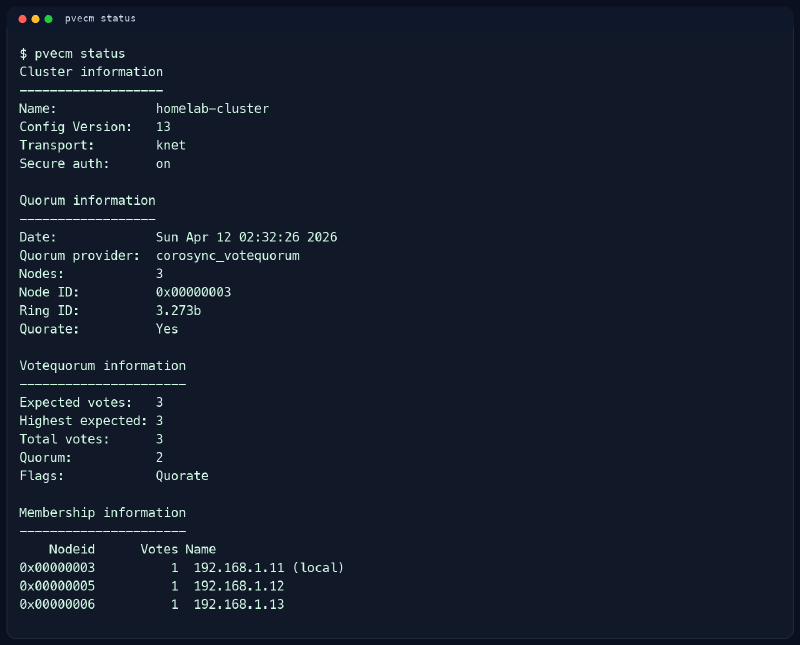
Aquí lo que busco es bastante concreto.
Lo primero es el Quorate: Yes. Parece obvio, pero no me quedo solo ahí. También miro Expected votes, Total votes y el número total de nodos. En un cluster de tres nodos quiero ver una historia coherente. Si espero tres votos y veo solo dos, el cluster puede seguir vivo, pero ya no está en una situación en la que me apetezca ponerme creativo.
También me fijo en la membresía. Quiero ver los tres nodos presentes y sin inventos raros. Cuando falta uno, el problema no es solo que falte uno. El problema es todo lo que deja de ser prudente hacer mientras no sé por qué falta.
A mí este comando me sirve para frenar impulsos. Muchas veces el error no está en actualizar Proxmox. El error está en hacerlo cuando el cluster ya venía cojo y tú te estabas engañando porque la interfaz no te gritó lo suficiente.
2. después miro HA porque el quorum solo no me da paz mental#
Un cluster puede tener quorum y seguir escondiendo cosas poco agradables. Por eso el segundo paso para mí es ha-manager status.
Esta salida también sale de una comprobación real, saneada para no enseñar datos internos del lab.
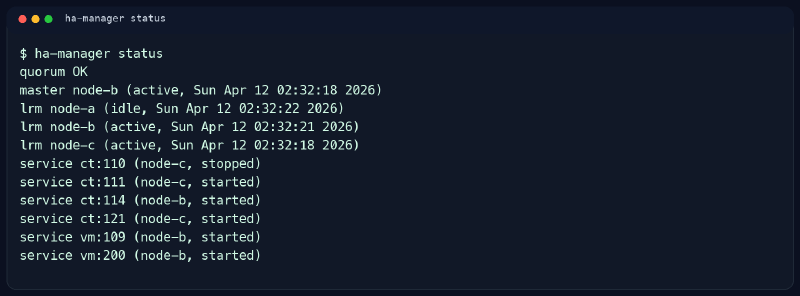
Aquí no busco poesía. Busco que la historia encaje.
Quiero ver un master activo, los lrm de cada nodo respondiendo y los servicios HA en un estado que tenga sentido. Si hay contenedores o VMs marcados como started, quiero que estén donde espero. Si algo está stopped, quiero saber si fue decisión mía o una sorpresa.
Lo que más desconfianza me produce no es ver algo parado. Lo que me pone en alerta es ver algo parado sin contexto. Porque cuando no recuerdas si eso estaba así a propósito, ya no estás operando infraestructura. Estás tirando de memoria borrosa, y la memoria borrosa en un cluster es una forma muy mediocre de documentación.
En mi rutina, si HA ya cuenta una historia rara, ahí paro. No salto a la siguiente pantalla con optimismo administrativo. Prefiero entender por qué ese servicio está donde está o por qué ese nodo figura como idle cuando esperaba otra cosa.
3. luego miro qué cargas están realmente vivas#
Después del estado de cluster y HA, suelo lanzar qm list y pct list. No necesito una auditoría completa. Necesito contexto operativo.
Quiero responder preguntas muy simples.
- ¿Qué VMs están corriendo ahora mismo?
- ¿Qué contenedores siguen activos?
- ¿Hay algo crítico viviendo justo en el nodo que pensaba tocar?
- ¿Voy a reiniciar un host que sostiene media tarde de inventos?
Esta parte me parece especialmente útil en homelab porque las cargas cambian mucho. Hoy una VM está encendida porque estás trasteando algo. Mañana ya no. Un contenedor puede pasar semanas parado y de repente volver a ser importante porque recuperaste un servicio. Si no miro ese inventario justo antes de tocar el nodo, corro el riesgo de trabajar con una foto antigua en la cabeza.
Y eso sale caro. A veces no en caída dura, pero sí en un montón de fricción innecesaria. Una migración que no hacía falta. Un reinicio que podías haber pospuesto. Un pequeño susto nocturno que nadie te pidió.
4. remato con storage porque muchos sustos empiezan ahí#
La cuarta pata de mi chequeo corto es el almacenamiento. No hace falta entrar a fondo todavía. Me basta con mirar pvesm status y confirmar que no haya algo cantando por lo bajini.
Lo curioso es que muchas veces el cluster parece sano hasta que llegas al almacenamiento y entonces ves un porcentaje incómodo, un storage inactivo o una capacidad que está más cerca del borde de lo que te gustaría admitir.
No hace falta esperar a la alarma dramática. Si el backup server está ya demasiado lleno o un storage aparece inactivo sin que sea algo esperado, yo lo anoto mentalmente como señal de prudencia. Puede que no me obligue a parar ese minuto, pero sí cambia mi tolerancia al riesgo.
Y aquí tengo una opinión bastante clara. Tocar un cluster que ya trae pequeñas rarezas de storage es la forma clásica de convertir una tarde normal en una sesión de arqueología digital.
qué me hace parar en seco#
No todo lo raro implica cancelar el día, pero hay unas cuantas señales que para mí son freno inmediato.
quorum dudoso o nodos ausentes#
Si pvecm status no me deja una historia limpia, no actualizo nada serio. Tampoco reinicio un nodo por comodidad. Primero resuelvo la salud del cluster.
HA inconsistente#
Si un recurso HA aparece en un estado que no entiendo, no lo racionalizo. Me obligo a entenderlo. El autoengaño técnico suele durar unos cuatro minutos y luego te pide intereses.
cargas críticas donde no esperaba#
Si voy a tocar un nodo y al listar VMs o contenedores descubro que tiene más trabajo del que recordaba, cambio el plan. Eso no me parece cobardía. Me parece administración sensata.
storage al límite o con estados raros#
Si uno de los destinos importantes ya va justo de capacidad o aparece inactivo sin explicación, mi tolerancia a los cambios baja bastante. No me gusta actualizar con un pie puesto en una cáscara de plátano.
lo que sí hago antes de actualizar o reiniciar#
Con el chequeo corto hecho, ya decido. Si todo cuadra, avanzo. Si no, no.
Cuando sí voy a tocar algo, mi secuencia suele ser bastante sobria.
Primero miro si el nodo que quiero tocar sostiene alguna carga que prefiera mover antes. Después verifico que HA no tenga nada raro pendiente. Si el cambio es de esos que podrían exigir un reboot, reviso otra vez quorum justo antes de lanzarme. No porque el comando vaya a cambiar por arte de magia, sino porque me gusta trabajar con una foto fresca y no con una de hace veinte minutos.
También intento separar tareas. Si voy a actualizar, actualizo. Si voy a mover VMs, muevo VMs. Mezclar varias operaciones porque ya estás metido suele ser la clase de idea que suena eficiente y luego termina en recreación histórica.
lo que no hago ya nunca#
Hay varias cosas que he dejado de hacer porque no compensan.
no reinicio un nodo solo porque ahora me viene bien#
Si no he mirado cluster, HA y cargas, no lo hago. Ni aunque en el panel parezca que sí. Ya me he ganado esa desconfianza a pulso.
no doy por hecho que un servicio parado es irrelevante#
He caído muchas veces en la trampa de pensar “eso está parado, luego no importa”. Luego resulta que importaba más de lo que recordaba o que estaba parado por un motivo que ya me convenía entender.
no hago cambios con el cluster sano a medias#
Esta es quizá la más importante. Un cluster pequeño no necesita heroicidad. Necesita disciplina. Si hoy algo ya viene ligeramente raro, mañana será mejor día para la alegría.
por qué esta rutina me ahorra tiempo aunque parezca lo contrario#
A alguien le puede sonar a paranoia. Yo creo que me ahorra problemas más de lo que me consume tiempo.
Entre lanzar pvecm status, ha-manager status, revisar cargas y echar un vistazo al storage, me gasto muy poco. Lo que gano a cambio es contexto real. Y el contexto real evita muchas decisiones torpes.
Además, esa rutina me obliga a pensar en el cluster como un sistema y no como una colección de nodos aislados. Esa diferencia se nota mucho cuando llevas meses tocando cosas. En un lab doméstico es fácil caer en el vicio de administrar a base de memoria y costumbre. El chequeo corto rompe justo ese piloto automático.
dónde encaja con el resto de mi forma de usar Proxmox#
Esta rutina no vive sola. Se apoya bastante en cómo tengo montado lo demás.
El hecho de tener claro por qué la red del cluster no puede ir mezclada con todo me ayuda a interpretar más rápido cuándo un problema puede venir de quorum y no de otra cosa. Haber repartido las cargas con cierta intención, como conté en Cómo reparto las VMs en mi cluster Proxmox para no convertir un nodo en el pringado de la casa, hace que mirar qm list y pct list tenga sentido de verdad. Y la experiencia de montar el conjunto en un cluster Proxmox de 3 nodos en mini PCs me dejó clara una verdad poco romántica. En homelab, la disciplina pequeña suele valer más que el gesto espectacular.
También enlaza con la discusión de LXC vs VM en Proxmox. Si sabes por qué cada carga vive donde vive, te resulta mucho más fácil decidir si un nodo se puede tocar o si hoy conviene dejarlo quieto.
mi checklist rápida, resumida#
Si me pillas delante de Proxmox a las dos de la mañana antes de tocar algo importante, probablemente estoy haciendo esto.
pvecm statusha-manager statusqm listypct listpvesm status
Si las cuatro piezas cuentan la misma historia, sigo. Si una empieza a mentir o a quedarse corta, no me pongo valiente. Me pongo curioso, que suele ser bastante más útil.
mi conclusión#
La salud de un cluster Proxmox no la decido por intuición ni por una UI bonita. La decido viendo si quorum, HA, cargas y storage cuentan una historia coherente al mismo tiempo.
A mí este chequeo me sirve porque es corto, repetible y bastante honesto. No pretende demostrar que tengo una disciplina militar. Pretende recordarme que un cluster pequeño perdona menos tonterías de las que uno cree cuando lleva una semana sin sustos.
Si usas Proxmox en casa y te gusta trastear, mi recomendación es simple. Antes de tocar nada mínimamente serio, regálate dos minutos de verdad. Mira el cluster, mira HA, mira qué está vivo y mira el almacenamiento. Ese tiempo parece poca cosa. La tranquilidad que compras con él no lo es.
Porque al final el objetivo no es ser valiente delante del botón de reinicio. El objetivo es no hacerte trampas con el estado real del lab.
referencias#
- Proxmox VE Cluster Manager
- High Availability en Proxmox VE
- Post relacionado: Corosync en Proxmox: por qué la red del cluster no puede ir mezclada con todo
- Post relacionado: Proxmox cluster de 3 nodos en mini PCs: lo que haría distinto después de montarlo en casa
- Post relacionado: Cómo reparto las VMs en mi cluster Proxmox para no convertir un nodo en el pringado de la casa
el mapa largo cuando el chequeo corto no basta#
El chequeo de dos minutos me sirve para decidir si puedo tocar el cluster. Pero hay días en los que esa primera foto no basta. Si veo quorum raro, nodos que aparecen y desaparecen o HA con cara torcida, entonces ya no sigo mirando comandos sueltos como si fueran estampitas. Los ordeno por capas.
La primera capa es membresía. Ahí entran pvecm status, pvecm nodes y, si necesito ver qué cree pmxcfs, cat /etc/pve/.members. No busco memorizar la salida. Busco coherencia. Si el cluster dice que espera tres votos, quiero ver tres nodos con una historia limpia. Si falta uno, no me invento una explicación cómoda.
La segunda capa es Corosync. Uso corosync-quorumtool -s para confirmar votos y quorum desde el lado de Corosync. Uso corosync-cfgtool -s para ver si los enlaces siguen vivos. Y si algo no me cuadra, reviso /etc/pve/corosync.conf para confirmar que los nombres, nodeid y direcciones siguen contando la misma historia que el hardware real.
La tercera capa son logs. Aquí journalctl -u corosync -n 80 --no-pager suele ser más útil que dar vueltas por la interfaz. No porque el terminal sea más serio, sino porque ahí aparecen los síntomas incómodos: enlaces que caen, knet protestando, cambios de membresía y nodos que vuelven como si nada. Cuando eso ocurre varias veces en poco tiempo, no es una anécdota. Es una señal.
La cuarta capa es HA. ha-manager status no arregla nada por sí mismo, pero me dice si Proxmox está intentando mover recursos, si un LRM está sano y si el manager ve el cluster como yo creo que lo ve. Si HA y quorum no cuentan la misma historia, paro. No hay premio por seguir.
La regla práctica es esta: si el problema parece de cluster, no empiezo por la VM que se queja. Empiezo por quorum, Corosync y pmxcfs. Muchas veces la VM solo es el síntoma visible de algo más bajo.
cuando miro cada cosa#
pvecm status: primera foto de quorum, votos y ring ID.pvecm nodes: lista corta de miembros y nodeid.cat /etc/pve/.members: lo que pmxcfs está exponiendo como mapa vivo del cluster.corosync-quorumtool -s: confirmación directa de quorum desde Corosync.corosync-cfgtool -s: estado de enlaces de cluster.journalctl -u corosync: eventos recientes de red de cluster.journalctl -u pve-cluster: problemas de pmxcfs cuando/etc/pveno inspira confianza.ha-manager status: estado del manager HA y de los recursos protegidos.
No hace falta lanzarlos todos cada vez. De hecho, si los lanzas todos por costumbre acabas leyendo sin mirar. La gracia está en elegir la capa correcta. Si no hay quorum claro, no pierdo tiempo en detalles de una VM. Si Corosync canta, miro red antes de mirar almacenamiento. Si pmxcfs no monta bien, no culpo al panel web.
Esto parece obvio escrito así. En caliente no lo es tanto. Por eso prefiero tener el flujo decidido antes de necesitarlo.