Los contenedores LXC en Proxmox tienen una virtud peligrosa. Son tan cómodos que acabas creando más de los que reconoces en público. Un proxy por aquí, una prueba de Debian por allá, un servicio pequeño que no merecía una VM completa, una utilidad que iba a ser temporal y lleva seis meses arrancando sola.
Por eso uso mucho pct config. Antes de cambiar red, memoria, disco, features o permisos de un contenedor, quiero ver su configuración real. No lo que creo que hice. No lo que recuerdo haber dejado. La realidad, con sus líneas feas y sus pequeñas pistas.
El comando es este.
| |
No tiene glamour. Tampoco lo necesita. En Proxmox, los comandos aburridos suelen ser los que te salvan cuando una tarde empieza a torcerse.
la captura real de este post#
La salida de la imagen sale de un contenedor real de mi laboratorio. He cambiado hostname, MAC, red, etiquetas y storage. También he quitado datos que no aportaban nada al artículo. Lo importante es la forma de leerlo.
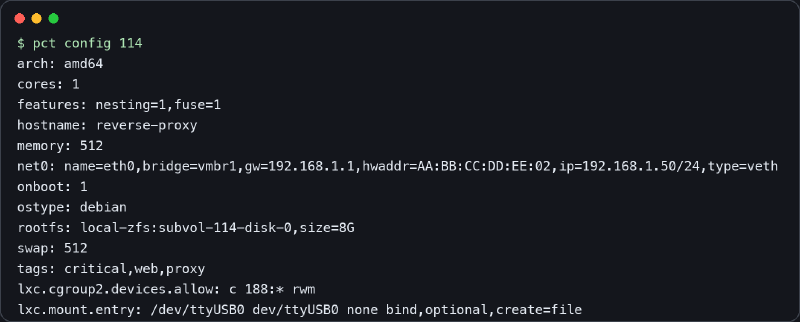
Me gusta esta salida porque enseña mucho en poco espacio. Arquitectura, CPU, memoria, red, disco raíz, swap, features y montajes. Si algo de eso está mal, el contenedor puede funcionar a medias y hacerte perder tiempo de una forma bastante tonta.
La interfaz web también lo enseña, claro. Pero cuando estoy conectado por SSH, pct config me da una fotografía rápida. Y si estoy documentando cambios, copiar esa salida a una nota interna es mucho más útil que confiar en que dentro de tres meses recordaré por qué ese contenedor tenía nesting activo.
por qué reviso LXC distinto a una VM#
Una VM tiene sus propios discos, su kernel invitado y una separación más clara. Un LXC vive más cerca del host. Esa cercanía es precisamente lo que lo hace rápido y ligero, pero también lo que vuelve importantes ciertas líneas de configuración.
En una VM me fijo mucho en BIOS, bus de disco, CPU y orden de arranque. En un contenedor miro con más cariño red, features, montajes, permisos y límites. Si un LXC necesita Docker dentro, nesting importa. Si tiene un dispositivo USB pasado desde el host, los lxc.mount.entry importan. Si tiene poca memoria, puede caer sin mucho teatro.
Por eso no trato pct config como una versión menor de qm config. Es otra lectura. Otra clase de riesgo.
hostname parece decorativo hasta que no lo es#
La línea de hostname suele ser sencilla.
| |
Parece poca cosa, pero ayuda a no perderse. En mi homelab intento que el nombre del contenedor diga qué hace, no cómo se me ocurrió llamarlo una noche. debian-test-2 puede valer durante diez minutos. Si seis meses después sigue ahí, el problema ya no es Proxmox.
Un buen hostname también ayuda cuando cruzas logs, backups, DHCP, DNS local y notas. No hace falta escribir poesía. Basta con que el nombre no sea mentira.
Cuando veo un contenedor con un hostname genérico, lo marco mentalmente como deuda. Quizá no lo arreglo en ese momento, pero ya sé que ahí hay una pieza mal identificada.
CPU y memoria: los contenedores también se pasan de rosca#
Estas líneas son las primeras que miro si el host va cargado.
| |
LXC invita a ser austero. Y muchas veces está bien. Un servicio pequeño puede vivir feliz con 512 MB. El problema aparece cuando el servicio dejó de ser pequeño y nadie actualizó los límites.
También pasa lo contrario. Contenedores con 4 GB para hacer el trabajo de un proceso que apenas respira. No es dramático si tienes recursos de sobra, pero en un nodo pequeño todo suma. Un homelab ordenado no necesita ser tacaño, pero sí debería saber dónde está gastando.
Me fijo también en swap. No porque usar swap sea pecado, sino porque me da contexto. Si un contenedor que debería ir sobrado empieza a apoyarse en swap, quizá el límite de memoria ya no encaja. Si un contenedor crítico tiene poca memoria y swap ridícula, quizá estoy pidiendo problemas.
rootfs me dice dónde vive el contenedor#
La línea de disco raíz merece atención.
| |
Aquí veo storage, tipo de volumen y tamaño. Si el contenedor está en un almacenamiento que no esperaba, paro. Si el tamaño es demasiado justo, lo apunto. Si vive en un storage que no entra en mi estrategia de backups, eso ya no es un detalle técnico. Es una amenaza lenta.
En casa he tenido contenedores pequeños que crecieron por logs, cachés o datos que nunca deberían haber vivido dentro del rootfs. pct config no te enseña el uso real del disco, para eso hace falta mirar dentro o consultar storage, pero sí te recuerda el límite. Y a veces ese recordatorio basta para detectar que vas justo.
Cuando el rootfs es pequeño, me pregunto si el contenedor guarda datos importantes dentro. Si la respuesta es sí, suelo revisar backups antes de tocar nada. Un contenedor ligero no significa un contenedor irrelevante.
la red es el sitio donde una línea decide demasiado#
Esta línea concentra muchas decisiones.
| |
Aquí miro el bridge, la puerta de enlace, la IP, el tipo de interfaz y la MAC. Si tienes una sola red plana, quizá parece excesivo. Si tienes VLANs, bridges separados o redes para servicios, esta línea manda.
Un contenedor en el bridge equivocado puede ser muy traicionero. A veces levanta, responde desde algún sitio y falla solo cuando intentas llegar desde otra red. Eso es peor que romperse del todo, porque te obliga a perseguir fantasmas.
También me gusta ver si la IP es estática o si depende de DHCP. No hay una única respuesta buena. Para contenedores de infraestructura prefiero IP fija o reserva bien documentada. Para pruebas me da igual. Lo que no quiero es no saberlo.
La MAC la saneo siempre que publico una captura. En privado me sirve para cruzar reservas DHCP o detectar duplicados raros. Son detalles pequeños hasta que te salvan.
features es la línea que explica muchas rarezas#
Esta es una de las líneas más importantes en LXC.
| |
Si un contenedor va a ejecutar Docker dentro, nesting suele aparecer. Si necesita ciertos sistemas de archivos o herramientas concretas, fuse puede importar. Cuando algo falla dentro de un LXC y en una VM funcionaba, miro features bastante pronto.
No activo features por costumbre. Cada permiso que acerco al host merece una razón. Tampoco me pongo paranoico con todo. Un homelab sirve para usar cosas, no para convertir cada contenedor en un expediente judicial. Pero quiero que las excepciones sean conscientes.
Cuando veo nesting=1, me pregunto si sigue haciendo falta. Si la respuesta es no, lo quito en la siguiente ventana tranquila. Si la respuesta es sí, lo documento mejor. Lo que no me gusta es encontrar features activas y no recordar por qué.
onboot revela qué contenedores se han vuelto importantes#
Esta línea siempre me interesa.
| |
Si arranca con el nodo, el contenedor forma parte del ecosistema vivo. Quizá es un proxy, un DNS, una automatización, un monitor o una cosa pequeña que ahora sostiene algo mayor. En un homelab hay servicios modestos que se vuelven críticos sin pedir permiso.
Antes de reiniciar un host miro qué LXCs tienen onboot activo. Si veo uno raro, reviso. Si un contenedor importante no lo tiene, también. Me gusta que el arranque del nodo sea predecible. No perfecto, porque esto es casa y siempre hay alguna ñapa, pero sí razonable.
El peligro está en dejar que todo arranque solo. Un nodo con demasiados servicios en onboot puede tardar más, consumir recursos de golpe y ocultar dependencias mal pensadas. A veces prefiero que ciertas pruebas sigan apagadas hasta que yo las necesite.
los montajes son donde dejo de ir deprisa#
Las líneas lxc.mount.entry son de las que leo despacio.
| |
Aquí ya estamos tocando la frontera entre host y contenedor. Puede ser un USB, una carpeta, un dispositivo o algo que el servicio necesita para funcionar. Si un contenedor tiene montajes, no lo trato como genérico.
Un montaje puede explicar por qué un servicio no arranca después de mover el contenedor. Puede explicar por qué un backup no tiene todo lo que creías. Puede explicar por qué una restauración en otro nodo no funciona igual.
En mi caso, cuando veo dispositivos pasados a un LXC, me pregunto tres cosas. Si el contenedor depende de ese hardware, si el nodo elegido tiene sentido y si existe un plan razonable cuando ese dispositivo falle o cambie de nombre.
No siempre hay una respuesta elegante. A veces la respuesta es “funciona y no lo toques mucho”. Perfecto. Pero al menos lo sabes.
las etiquetas deberían avisarte, no decorar#
Uso tags porque ayudan, pero intento no convertirlas en confeti.
| |
Una etiqueta como critical debe doler un poco. Si todo es crítico, nada lo es. Si un contenedor tiene esa etiqueta, antes de pararlo miro dos veces. Si no la tiene y debería, lo corrijo.
Las tags también ayudan a separar pruebas de servicios reales. En un homelab con muchos contenedores, esa diferencia ahorra bastante ruido. No quiero abrir Proxmox y ver una lista de nombres donde todo parece igual.
Para mí, una buena etiqueta responde rápido a una pregunta. ¿Qué es esto y cuánto cuidado merece? Si no responde eso, sobra o está mal elegida.
mi rutina antes de tocar un LXC#
Antes de cambiar un contenedor suelo hacer una secuencia corta.
| |
Primero veo si está corriendo. Luego leo la configuración. Después compruebo si hay cambios pendientes. Si voy a tocar red, saco captura o copio la línea actual. Si voy a tocar features o montajes, me tomo más calma.
También reviso backups si el contenedor tiene datos que importan. La ligereza de LXC engaña. Un contenedor puede ocupar poco y aun así ser doloroso de reconstruir porque contiene configuración, certificados, una base de datos pequeña o el típico script que solo existe ahí porque nadie lo subió a Git.
Si voy a cambiar IP o bridge, prefiero tener abierta una vía de acceso alternativa al nodo. Romper la red de un contenedor no suele ser grave. Romper la ruta mental para volver a dejarlo como estaba sí es una pérdida de tiempo absurda.
cuándo prefiero VM en vez de LXC#
Me gustan mucho los contenedores, pero no los uso para todo. Si necesito aislamiento fuerte, kernel propio, drivers raros o una aplicación que se pelea con LXC, hago una VM y duermo mejor.
También prefiero VM cuando el servicio va a moverse entre nodos con menos dependencia del host. LXC puede migrar, pero los montajes, dispositivos y features hacen que algunas migraciones sean menos limpias de lo que prometía la idea inicial.
Mi regla práctica es sencilla. Si el servicio es pequeño, controlado y encaja bien con el host, LXC. Si empieza a pedir demasiadas excepciones, quizá está intentando decirme que quería ser una VM desde el principio.
lo que no enseña pct config#
pct config no te dice si el servicio dentro está sano. No ve si nginx tiene una configuración rota, si un contenedor Docker interno está caído o si una tarea cron lleva semanas fallando. Para eso hacen falta logs, monitorización y entrar dentro.
Tampoco te da uso real de CPU o memoria en histórico. Te enseña límites y definición. Esa distinción importa. Una cosa es saber cuánta RAM puede usar y otra saber cuánta está usando a las tres de la tarde cuando todos los servicios despiertan.
Pero como punto de partida, me parece excelente. Antes de tocar, leo. Antes de culpar, leo. Antes de migrar, leo con más atención.
mi opinión#
pct config es un comando humilde, pero en Proxmox le tengo bastante respeto. Los contenedores son cómodos y por eso mismo pueden acumular decisiones invisibles. Un bridge cambiado, una feature activada, un montaje a un dispositivo del host, un onboot que nadie recuerda. Todo eso vive ahí.
No hace falta obsesionarse. Basta con incorporarlo a la rutina. Cuando un LXC importa, pct config va antes del cambio. Es una pausa breve, seca y útil.
A mí esa pausa me ha evitado tocar contenedores equivocados, mover servicios con dependencias raras y reiniciar cosas que tenían más papel del que parecía. No es épico. Mejor. La épica en infraestructura doméstica casi siempre significa que alguien hizo algo mal antes.
Si estás ordenando tu Proxmox, yo lo pondría al lado de pct list, pvesm status y pvecm status. Inventario primero, decisiones después. Es menos emocionante que probar otro servicio nuevo, pero bastante más barato en horas perdidas.