Hay una clase de fallo que me parece bastante peor que un error claro. El fallo silencioso. El que no rompe con estruendo, no manda una alarma espectacular y no te deja un log rojo diciendo “esto ha salido mal”. Solo sigue adelante, aparenta normalidad y mientras tanto te está preparando una hostia para más tarde.
Eso fue exactamente lo que me obsesionó con mis backups por NFS. El problema no era que el backup remoto se cayera. Eso puede pasar. El problema era algo más traicionero. El montaje remoto no estaba donde debía, el script aún tenía un camino alternativo local, y la combinación de ambas cosas podía convertir una copia supuestamente segura en un proceso bastante eficiente llenando el disco del host.
Cuando vi el patrón con calma me di cuenta de que el error no era de NFS. El error era mío por confiar en exceso en una ruta y no obligar al script a demostrar que el destino remoto estaba realmente montado antes de escribir nada serio. Desde entonces ya no doy por bueno ningún backup que dependa de un montaje de red si antes no pasa una serie de comprobaciones muy básicas.
Y cuanto más lo pienso, más me parece una de esas lecciones que conviene aprender pronto en cualquier homelab. Porque la gente habla mucho del backup 3-2-1, de ZFS, de Proxmox Backup Server, de snapshots y de replicación. Todo eso importa. Pero antes de llegar ahí hay una pregunta mucho más humilde y mucho más importante. ¿Estás escribiendo de verdad donde crees que estás escribiendo?
el día que el backup dejó de parecer una buena idea#
Lo que tenía era un caso bastante típico. El backup principal debía ir a un recurso montado por red. En papel sonaba perfecto. El host genera el tarball, lo deja en el destino remoto y todos contentos. Mientras el montaje está bien, así funciona.
La trampa es lo que pasa cuando ese montaje desaparece o no está listo en el momento de ejecutar el trabajo. Si el script solo mira una ruta bonita y no verifica el montaje real, puede empezar a escribir en local con una tranquilidad pasmosa. A veces porque hay un fallback explícito. A veces porque el directorio de montaje existe aunque el recurso remoto no esté montado encima. Y ahí es donde empieza la fiesta mala.
En mi caso acabé endureciendo el script porque el Mac ya iba muy justo de disco. La situación real aquella noche era esta.
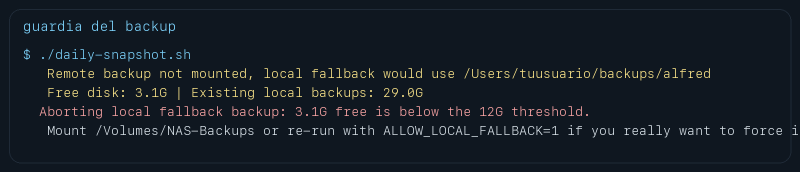
Eso, para mí, es la diferencia entre un backup sensato y un suicidio administrativo. El script ve que el remoto no está montado, mira el espacio libre local, ve que no alcanza el umbral de seguridad y aborta. Sin heroicidades. Sin optimismo absurdo. Sin fabricar otro archivo de varios gigas que luego me dejaría el host pidiendo oxígeno.
El dato que me hizo apretar los dientes fue muy simple. Quedaban 3.1 GB libres y ya había 29 GB en copias locales previas. Si ahí dejo correr el backup por inercia, no estoy protegiendo nada. Estoy empeorando dos problemas a la vez.
por qué este fallo es tan traicionero#
Hay errores que saltan a la vista. Un SSH que no conecta. Un rsync que devuelve error. Un contenedor que no arranca. Esto no.
Este tipo de fallo es traicionero por varias razones.
La primera es que las rutas siguen existiendo. Si tu script apunta a /mnt/backups o a /Volumes/NAS-Backups, esa carpeta puede seguir ahí aunque el recurso remoto ya no esté montado. A muchos scripts les basta con ver que la ruta existe para seguir adelante. Grave error.
La segunda es que las herramientas de copia no tienen contexto emocional. tar, rsync o la utilidad que uses hacen lo que les dices. Si el destino visible es una carpeta local vacía porque el montaje cayó, escribirán ahí con entusiasmo profesional.
La tercera es que durante un rato todo parece ir bien. El backup termina, deja un archivo, actualiza fechas y quizá hasta imprime un bonito “complete”. El desastre llega después, cuando ves que el disco local baja sin explicación aparente o cuando descubres que tus supuestas copias remotas nunca salieron del host.
Y la cuarta, que me parece la peor, es la falsa sensación de seguridad. Crees que tienes una estrategia de backup funcionando cuando en realidad tienes un mecanismo bastante eficaz para duplicar datos en el mismo sitio que intentabas proteger.
NFS no es el villano, la confianza ciega sí#
No le echo la culpa a NFS. De hecho me sigue pareciendo una solución perfectamente válida para muchos homelabs. El problema aparece cuando lo tratas como si fuera una pared de hormigón y no una dependencia de red más, con sus tiempos, sus reinicios, sus desmontajes, sus boots raros y sus momentos de ausencia.
Un share NFS puede no montarse al arrancar porque la red todavía no estaba lista. Puede caerse porque el NAS reinició. Puede desaparecer un rato por una actualización. Puede no estar accesible justo cuando corre el cron. Todo eso entra dentro de lo normal. Lo que no debería ser normal es que tu script no se entere.
Por eso me gusta separar la discusión.
- NFS es un transporte o un destino razonable.
- Mi script es quien tiene que ganarse el derecho a confiar en él.
Cuando haces esa separación mental, empiezas a meter salvaguardas de verdad en vez de rezar.
la comprobación que me parece obligatoria#
La utilidad mountpoint hace justo lo que promete. Comprueba si una ruta es un punto de montaje de verdad. El manual es bastante claro y por eso me gusta usarlo como guardia en la puerta. Si la ruta no es un mountpoint real, el script no debería seguir como si nada.
En mi versión endurecida, la lógica es muy simple.
- Compruebo si la ruta remota existe.
- Compruebo si esa ruta está realmente montada.
- Solo entonces acepto el destino remoto como válido.
- Si no lo está, paso al plan B con límites muy claros.
El punto importante es que el plan B ya no es libre. Antes un fallback local podía parecer una solución razonable. Ahora solo lo permito si el disco tiene margen suficiente o si yo lo fuerzo de forma explícita. Si no, se bloquea.
Esa combinación me gusta mucho más que confiar en una comprobación superficial del tipo “la carpeta existe”. Una carpeta vacía no es un backup remoto. Es una trampa con buen aspecto.
lo que cambié en el script y por qué#
La versión actual hace cuatro cosas que para mí ya son mínimas.
comprueba el montaje real#
Sin esto no hay conversación. Si el destino remoto no es mountpoint real, no lo trato como remoto. Punto.
mira el espacio libre local antes de aceptar un fallback#
Esto me parece importantísimo. Un fallback local puede ser útil si el host tiene espacio de sobra y quieres no perder una ventana de backup puntual. Pero si el host está justo, el fallback no es una red de seguridad. Es una fuga.
Yo fijé un umbral mínimo de disco libre. Si el sistema cae por debajo, el script aborta. Prefiero una copia no hecha y una alerta clara a una copia local que deje el host al borde del colapso.
escribe estado estructurado#
Esto parece una tontería hasta que te salva una mañana. Además del log en consola, el script deja un pequeño JSON con estado, destino, espacio libre y razón. Gracias a eso otras automatizaciones pueden ver si el último backup fue remoto, local, bloqueado o sospechoso.
La salida saneada que me queda ahora es algo así.
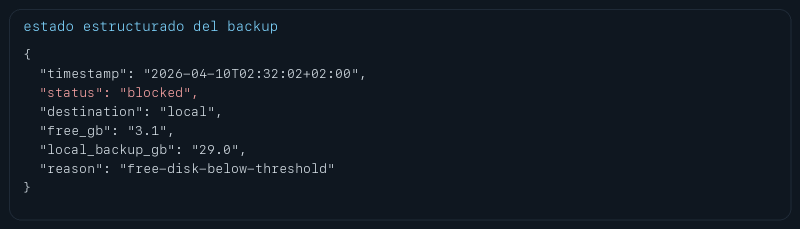
Ese archivo no es glamour técnico, pero es justo la clase de aburrimiento útil que luego te evita preguntas idiotas a las siete de la mañana.
obliga a forzar el fallback si de verdad quiero asumir el riesgo#
Esto también lo cambié a propósito. Si quiero permitir backup local a pesar de todo, tengo que hacerlo con una variable explícita. Nada de comportamiento optimista por defecto. Si voy a correr ese riesgo, que sea consciente.
Me gusta mucho esta idea en automatización casera. Cuando una acción peligrosa sigue siendo posible, pero deja de ser la ruta fácil, el sistema ya te está ayudando a no hacer tonterías por inercia.
el patrón que me parece peligroso de verdad#
El patrón peligroso no es usar NFS. El patrón peligroso es este.
- Montaje remoto asumido pero no verificado
- Creación automática del directorio de destino sin distinguir si es remoto o local
- Fallback local sin comprobar espacio
- Mensaje de éxito aunque la copia terminó en el sitio equivocado
Si veo esas cuatro cosas en un script de backup, desconfío al instante. Porque no es un problema de si va a fallar o no. Es un problema de cuánto tiempo tardarás en enterarte de que falló.
La parte más irritante es que corregirlo no exige montar una nave espacial. Son comprobaciones bastante simples. La lección aquí no es que el backup sea complejo. La lección es que nos volvemos peligrosos cuando simplificamos justo la parte que valida la realidad.
lo que haría si empezara hoy desde cero#
Si tuviera que rehacer un esquema de backups por red para un homelab doméstico, empezaría por esto.
1. destino remoto y fallback local en rutas claramente distintas#
Nada de escribir en un subdirectorio del mismo árbol esperando que la magia haga el resto. Quiero que el destino remoto y el fallback local sean inequívocos para el script y para mí.
2. verificación con mountpoint antes de escribir un byte#
No una vez al montar. No como parte de una checklist mental. En el propio script y en la misma ejecución que va a generar el backup.
3. umbral mínimo de disco local#
Si el host está justo, el fallback local queda bloqueado. Sin discusión.
4. archivo de estado legible por otras tareas#
Si luego quieres mandar una alerta, mostrar un panel o decidir si repetir la tarea, ese estado ya está ahí.
5. alerta cuando el backup remoto no ocurrió#
No hace falta spam. Hace falta señal útil. Si tres ejecuciones seguidas caen en local, o una se bloquea por falta de espacio, quiero saberlo antes de que el sistema me lo grite con un disco al 99 por ciento.
6. limpiar el almacenamiento local con intención#
El fallback local no puede convertirse en un cementerio silencioso. Si existe, tiene retención clara y límites claros.
dónde encaja esto en una estrategia de backup seria#
Esto no sustituye una estrategia de backup de verdad. La refuerza.
Puedes tener muy buena teoría y aun así perder por algo muy tonto. Puedes saberte de memoria la regla 3-2-1 y luego descubrir que una de tus copias no salía del mismo host. Puedes tener snapshots de ZFS y aun así dejar que un trabajo automático te llene el disco del nodo. Puedes tener restic, Proxmox Backup Server o el NAS más simpático del mercado y seguir siendo vulnerable si el paso uno falla en silencio.
Por eso para mí esta capa de validación va antes que todo lo demás. Primero demuestro que escribo donde creo que escribo. Luego ya discutimos rotación, compresión, cifrado o retención.
Si te interesan más piezas de esa parte alta de la estrategia, ya hablé de Backup 3-2-1: protege tu homelab de desastres, de Restic: backups incrementales para homelab y de ZFS snapshots: el sistema de backups que deberías usar en tu homelab. Este post vive un escalón antes. Justo donde decides si la copia está saliendo del sitio o se está quedando a vivir contigo sin avisar.
la parte menos sexy y más útil#
Hay mucho contenido de homelab que se enamora de la herramienta y muy poco que se pare a mirar los bordes feos. A mí cada vez me interesan más esos bordes.
No me impresiona un backup porque use una herramienta moderna. Me impresiona cuando falla de forma limpia. Cuando bloquea un comportamiento peligroso. Cuando deja una pista clara de por qué no siguió. Cuando me obliga a confirmar una decisión mala en vez de asumirla por mí. Ahí es donde noto que el sistema está bien pensado.
Con los años he acabado valorando más esa clase de fiabilidad aburrida que la brillantez de un panel precioso. Un backup que no miente vale más que un backup que parece elegante. Y uno que se niega a llenar el disco local cuando el remoto no está disponible vale todavía más.
mi conclusión#
Si haces backups sobre NFS o cualquier otro montaje de red, no asumas nada. Verifica. Siempre.
Verifica que el destino remoto está realmente montado. Verifica que el fallback local tiene sentido antes de usarlo. Verifica que el host puede soportarlo. Deja estado legible. Y si algo no cuadra, aborta con mala leche y a tiempo.
Yo prefiero mil veces un backup cancelado por prudencia a un backup aparentemente exitoso que luego descubro ocupando el mismo disco que intentaba proteger. El primero me da trabajo. El segundo me regala una falsa seguridad y una avería nueva. Y esa combinación es bastante peor.
Así que sí, NFS me sigue pareciendo útil en homelab. Lo que ya no me parece aceptable es tratarlo como si no pudiera desaparecer nunca. Un montaje de red no es una promesa. Es una condición. Y si el script no la comprueba, el problema no está en NFS. El problema está en el script.
referencias#
- mountpoint(1) manual page
- Post relacionado: Backup 3-2-1: protege tu homelab de desastres
- Post relacionado: Restic: backups incrementales para homelab
- Post relacionado: ZFS snapshots: el sistema de backups que deberías usar en tu homelab