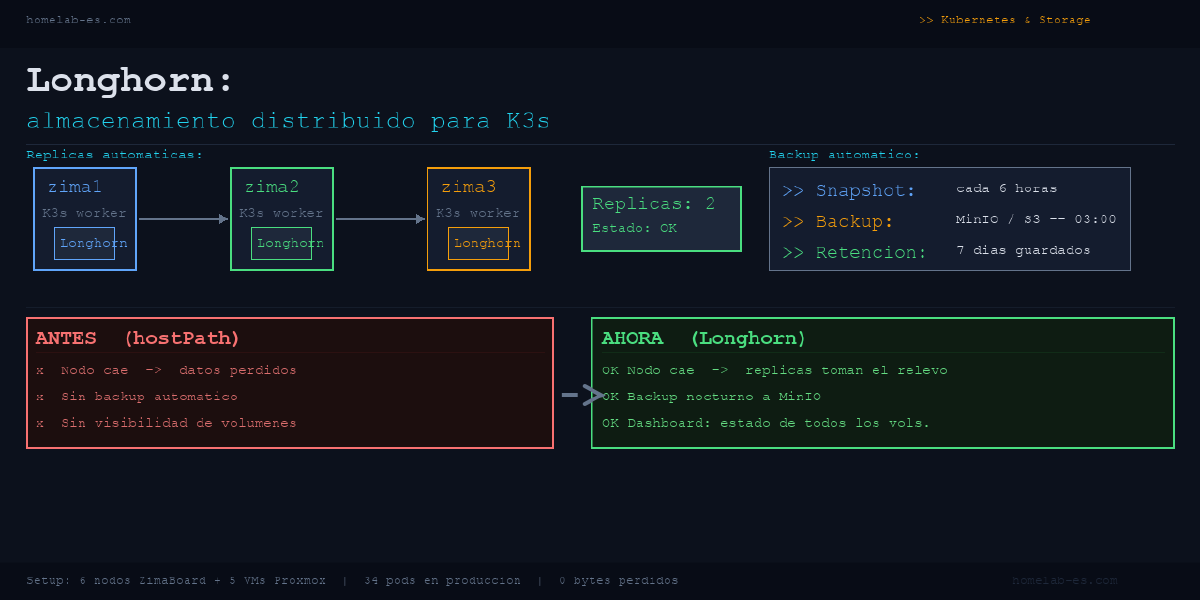
Durante meses guardé los datos de mis aplicaciones en Kubernetes con hostPath: un directorio del nodo. Simple, rápido, sin dependencias. Y un día un nodo se cayó y me llevó por delante los datos de Jellyfin, tres meses de configuración de Sonarr y la base de datos de mi Gitea personal.
Ese día instalé Longhorn.
Longhorn es el sistema de almacenamiento distribuido que Rancher mantiene como proyecto oficial para Kubernetes. La idea es simple: en vez de guardar tus datos en un solo nodo, los replica en varios. Si un nodo muere, tus datos siguen ahí en los otros.
Si tienes un clúster K3s con más de un nodo y todavía no usas almacenamiento distribuido, este post es para ti.
Qué es Longhorn exactamente#
Longhorn convierte el disco local de cada nodo en bloques de almacenamiento que el clúster puede usar como si fueran discos virtuales. Cuando un pod necesita un volumen, Longhorn lo crea, lo replica en los nodos que elijas (por defecto en 3), y lo monta.
Lo que resuelve en la práctica:
- Alta disponibilidad: tus datos sobreviven si un nodo cae
- Backups automáticos: snapshots programables y backup a S3/MinIO
- UI decente: tiene dashboard propio para ver el estado de los volúmenes
- Snapshots: puedes volver a un estado anterior de cualquier volumen
Lo que cuesta:
- Usa IOPS de red entre nodos para las réplicas
- Consume algo más de disco (×N según réplicas)
- En nodos con pocos recursos, puede ser notorio
En mi setup de 6 ZimaBoard en un clúster K3s con 3 nodos más de Proxmox, lo uso para todo excepto los volúmenes de solo lectura.
Requisitos previos#
- Clúster K3s funcionando con al menos 2 nodos (con 3+ es mucho mejor)
kubectlconfigurado y apuntando al clúster- Mínimo 2GB de RAM libre por nodo que vaya a usar Longhorn
open-iscsiinstalado en los nodos (te explico cómo)- Opcional pero recomendado: MinIO o cualquier bucket S3 para backups
Instalar dependencias en los nodos#
Longhorn necesita open-iscsi en cada nodo que vaya a almacenar datos. Hay que instalarlo antes de nada:
| |
Si tienes muchos nodos, un bucle ayuda:
| |
También necesitas nfs-common si quieres usar ReadWriteMany:
| |
Verificar el entorno#
Longhorn tiene un checker oficial que detecta problemas antes de instalar:
| |
Instalación#
Opción 1: Helm (recomendado)#
| |
El parámetro defaultReplicaCount=2 es importante si tienes solo 2-3 nodos. Con 3 réplicas en un clúster de 3 nodos no te queda margen de fallo.
Opción 2: Manifiestos directos#
| |
Verificar la instalación#
| |
Espera hasta que todos estén en Running. Puede tardar 3-5 minutos la primera vez.
| |
Deberías ver longhorn y longhorn-static como StorageClasses disponibles.
Acceder al dashboard#
Longhorn incluye una UI propia. Para accederla en local:
| |
Abre http://localhost:8090 y verás el estado de tus nodos, volúmenes y réplicas.
Si tienes Traefik o Ingress configurado, puedes exponerlo permanentemente:
| |
Usar Longhorn en tus aplicaciones#
Una vez instalado, puedes usarlo como cualquier StorageClass. En tu PVC:
| |
Longhorn se encarga de crear el volumen, replicarlo y montarlo donde el pod lo necesite.
Configurar backups a MinIO#
Esta es la parte que más valor aporta. Con backups automáticos puedes recuperarte de cualquier desastre.
Configurar MinIO como destino#
Si ya tienes MinIO en tu homelab, crea un bucket específico para Longhorn:
| |
Configurar Longhorn para usar ese bucket#
En el dashboard, ve a Settings → Backup Target y pon:
| |
Y en Backup Target Credential Secret, crea primero el secret:
| |
| |
Programar backups automáticos#
En el dashboard, por volumen puedes configurar un Recurring Job. O via YAML para aplicarlo a todos:
| |
Esto hace backup de todos los volúmenes marcados con el grupo default cada noche a las 3h, guardando los últimos 7.
Problemas habituales y cómo resolverlos#
Los pods se quedan en ContainerCreating#
Casi siempre es open-iscsi no instalado en algún nodo, o iscsid no arrancado. Verifica:
| |
Un nodo está en “Not Ready” en el dashboard#
Longhorn tiene su propio health check independiente del de Kubernetes. Puede que el nodo esté Ready en K3s pero Longhorn lo vea mal. Mira los logs del longhorn-manager en ese nodo:
| |
Los volúmenes se degradan si apagas un nodo#
Normal. Con replicaCount=2 y 3 nodos, si apagas uno te queda 1 réplica y Longhorn te avisa de que el volumen está degradado. No es un error, es que está trabajando con menos redundancia temporalmente. Cuando el nodo vuelve, se rebalancea solo.
Rendimiento lento en ZimaBoard o hardware con eMMC#
El almacenamiento eMMC de las ZimaBoard no es rápido. Si notas lentitud, usa discos USB 3.0 o NVMe externos y configura Longhorn para usarlos específicamente con node selectors.
Mi configuración actual#
En mi clúster tengo:
- 3 nodos Longhorn (ZimaBoard) con almacenamiento local
- 3 nodos Longhorn adicionales (VMs en Proxmox) para los datos más críticos
- Réplicas: 2 para apps de media, 3 para bases de datos y Gitea
- Backups nocturnos a MinIO en Phatt
- Snapshots cada 6 horas para las apps con más escrituras
Las apps de media (Jellyfin, Sonarr, Radarr) usan réplicas x2. Las bases de datos y todo lo que sería doloroso reconstruir usan x3.
Desde que lo monté no he perdido ni un byte.
¿Merece la pena para un homelab pequeño?#
Si tienes un solo nodo, no. Para un nodo usa hostPath o un NFS externo, Longhorn no aporta nada sin réplicas reales.
Si tienes 2 nodos o más y usas Kubernetes para algo que te importa (datos personales, configuraciones que tardaste en hacer, servicios que usan otros), sí. El coste en recursos es asumible y la tranquilidad de saber que un nodo caído no te borra los datos no tiene precio.
El dashboard es un bonus: poder ver el estado de todos tus volúmenes en una pantalla hace que gestionar el almacenamiento sea mucho menos opaco que con hostPath y un listado de directorios.
¿Tienes preguntas sobre la configuración? Deja un comentario. Si te pasó lo mismo que a mí con el hostPath, cuenta tu historia.