Hay fallos que se agradecen porque son honestos. El servicio no arranca, el nodo se cae o el storage sale claramente inactivo y ya sabes que toca arreglar algo. Luego están los otros, los que te miran a la cara con media verdad. Esta madrugada me encontré justo uno de esos en Proxmox.
Tenía un storage CIFS configurado en el cluster para usarlo con ISOs, backups puntuales y algún archivo compartido. Nada exótico. Lo raro fue esto. En dos nodos el recurso seguía apareciendo montado, el mount lo enseñaba sin rubor y, si te quedabas en la superficie, podías pensar que el problema era menor. Pero en cuanto intentaba tocar ese punto de montaje con df -h, la respuesta era bastante menos diplomática. Host is down.
Ahí es donde me gusta frenar. Porque un recurso que está claramente caído molesta, sí, pero al menos no engaña. Uno que parece seguir montado y luego se deshace al primer contacto es bastante más traicionero. Sobre todo en un homelab donde muchas automatizaciones dependen de comprobaciones rápidas y no siempre hacen una validación profunda del destino.
por qué este fallo me molesta más que un offline limpio#
Si Proxmox me dice que un storage CIFS está inactivo en todos los sitios y además el sistema no mantiene ningún montaje colgado, la historia está bastante clara. Hay un destino que no responde y toca revisar red, NAS, credenciales o servicio SMB. No es agradable, pero tampoco hay demasiada ambigüedad.
Lo que me encontré aquí fue una mezcla bastante peor.
pvesm statusmarcaba el storage como inactivo en los tres nodosmountseguía mostrando el recurso CIFS en dos de ellosdf -hcontra el punto de montaje devolvíaHost is down- el host del NAS no respondía ni a un
pingsimple
Esa combinación es la clase de cosa que invita al autoengaño si vas con prisa. Puedes pensar que el montaje sigue ahí y que ya volverá. Puedes asumir que es un fallo temporal porque la línea aún existe en mount. Puedes incluso olvidarte del tema porque el cluster sigue con quorum y las VMs continúan su vida. Y justo así es como empiezan muchas historias tontas en homelab.
A mí no me preocupa solo que el recurso esté caído. Me preocupa más no tener claro en qué estado real está el nodo respecto a ese recurso. Porque si una tarea automática ve un path que sigue existiendo pero no valida que el destino responda, el siguiente capítulo suele ser feo. O falla el job, o se queda colgado esperando I/O, o peor, hace un fallback a otro sitio local y te llena un disco que no estaba invitado a la fiesta.
la captura que me hizo parar#
Esta salida está saneada, pero sale de una comprobación real del cluster.
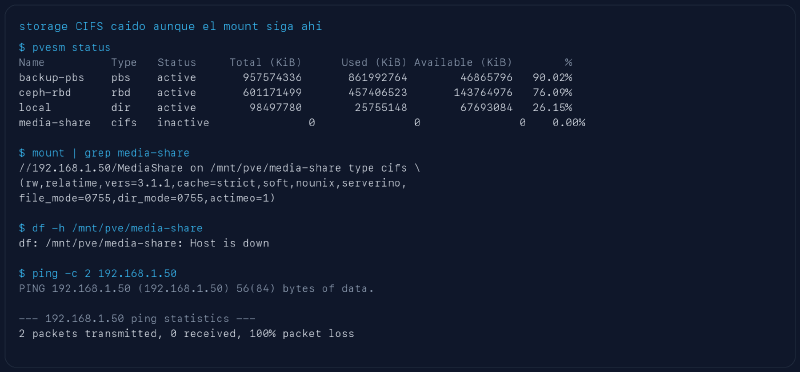
Lo que veo ahí me cuenta bastante.
Primero, pvesm status ya deja claro que media-share está inactive. Hasta aquí nada raro. El detalle interesante viene después. El sistema sigue enseñando la línea del montaje CIFS en el nodo, con sus opciones, su versión SMB y su path de siempre. Si te quedas solo con eso, puedes caer en la trampa de pensar que el montaje aún vive.
Pero en cuanto le pides una operación real que obligue a hablar con el servidor remoto, se acabó la ilusión. df -h /mnt/pve/media-share responde Host is down. El ping al NAS también falla con un cien por cien de pérdida.
Para mí eso no es un matiz sin importancia. Es justo la diferencia entre “el sistema recuerda un montaje” y “el recurso está realmente usable”. Son dos cosas muy distintas.
cómo interpreto esta combinación sin inventarme teorías raras#
No hace falta ponerse místico. Cuando veo este patrón suelo asumir algo bastante simple. El nodo conserva el rastro del montaje, pero la conectividad real con el servidor SMB ya no existe o no es usable en ese momento.
Las causas pueden variar.
- el NAS está apagado o colgado
- hay un problema de red entre el nodo y esa subred
- el recurso SMB dejó de responder aunque la ruta siga montada a nivel de kernel
- hubo un corte previo y el cliente CIFS mantiene el punto de montaje en un estado zombi
Lo importante para mí no es adivinar la causa exacta en el primer minuto. Lo importante es no confundir presencia visual con salud operativa.
En Proxmox esto importa bastante porque el storage no es decoración. Si ese recurso tiene contenido permitido para backup, iso, images o snippets, tarde o temprano algo va a intentar usarlo. Y si la comprobación que haces es superficial, te puedes llevar una sorpresa justo cuando menos te viene bien.
la primera capa que reviso siempre es storage.cfg#
Cuando un storage compartido se pone raro, quiero confirmar tres cosas sin dar rodeos.
- cómo está definido en el cluster
- qué tipo de contenido admite
- si el problema es de definición o de acceso real
En mi caso la definición era la típica de un CIFS en Proxmox. Path bajo /mnt/pve, share remoto y varios tipos de contenido habilitados. Nada especialmente creativo. Eso me sirve para una lectura práctica. Si ahí veo que el storage solo guarda ISOs viejas, la urgencia es una. Si además admite backups o discos de VM, la urgencia cambia bastante.
Yo no recomiendo tener demasiados roles mezclados en un único CIFS, precisamente por esto. Cuando un storage remoto se cae, cuanto más heterogéneo sea su uso, más difícil es decidir rápido el impacto real.
lo que me dijo mount y por qué no me tranquilizó nada#
Hay gente que al ver la línea en mount respira. Yo no.
mount te dice que el kernel sigue considerando ese punto de montaje como montado. No te promete que el servidor del otro lado esté vivo, rápido ni mínimamente cooperativo. En recursos de red, esa diferencia importa muchísimo.
De hecho, una de las peores cosas que puedes hacer es quedarte satisfecho con esa comprobación. En local casi siempre basta. En NFS o CIFS me parece demasiado optimista.
Yo prefiero validar con una operación que de verdad toque el remoto. df -h, ls sobre un directorio concreto si no hay riesgo de bloqueo, o cualquier lectura pequeña que me confirme que el recurso responde. Y si esa prueba básica ya devuelve Host is down, para mí se acabó la discusión. El storage no está sano, aunque siga apareciendo en la lista de montajes.
el detalle del ping también me ahorró tiempo#
El ping no resuelve toda la historia, pero aquí sí me ayudó a decidir por dónde no perder tiempo. Si el host remoto ni siquiera responde a ICMP desde los tres nodos, es bastante poco probable que el problema esté solo en una opción fina de SMB o en un permiso puntual del share.
No siempre uso ICMP como juez absoluto. Hay equipos que lo bloquean y listo. Pero en una red doméstica o de lab, donde normalmente sí esperas respuesta, perder el ping en los tres nodos me apunta más a host caído, ruta rota o segmento inaccesible que a una tontería del cliente CIFS.
Eso me evita una pérdida de tiempo muy concreta. No me pongo a discutir con Proxmox si antes no sé si el NAS respira.
por qué me preocupa tanto en automatizaciones#
La razón real de mi mala leche con este tipo de fallos está en las tareas automáticas. Un recurso de red medio muerto es mucho más peligroso para una automatización que para un humano atento.
Un humano entra, ve cosas raras y para.
Un script mal planteado hace otra cosa. Ve que el path existe, asume que el destino vale y sigue. Luego vienen los clásicos.
- jobs que se quedan colgados demasiado tiempo
- copias que fallan a mitad
- procesos que escriben en local porque el guard era flojo
- alertas ruidosas que no explican bien la causa
Hace poco conté algo emparentado en Backups por NFS en homelab: cómo valido el montaje antes de llenar el disco local. El protocolo no era el mismo, pero la lección sí. Un punto de montaje de red no se da por bueno solo porque exista. Se valida como si desconfiaras de él. Porque a veces toca hacerlo.
mi forma de decidir si esto es urgente o solo incómodo#
No todos los storages caídos merecen correr por casa con una linterna. Yo suelo hacerme estas preguntas.
¿Qué contenido vive ahí?#
Si el CIFS solo guarda material poco crítico, la caída puede esperar unas horas. Si participa en backups, plantillas o imágenes de VM, ya me interesa bastante más entender el alcance.
¿Hay tareas programadas que dependan de ese path?#
Esta es la pregunta que más pesa. Un storage remoto muerto pero olvidado molesta menos que uno del que cuelgan jobs nocturnos.
¿El problema es global o de un nodo?#
Aquí fue global. Los tres nodos mostraban el storage inactivo y ninguno alcanzaba el host remoto. Eso cambia mucho la lectura. Si solo fallara en un nodo, mi sospecha se movería más hacia routing local, firewall o un cliente tocado.
¿Hay fallback peligroso?#
Si alguna tarea puede redirigirse a almacenamiento local cuando el remoto no responde, quiero bloquearla antes de que haga el idiota.
lo que haría yo en este orden#
Mi secuencia cuando veo algo así suele ser bastante simple.
- Confirmar si el host remoto responde desde al menos un nodo.
- Ver si el share CIFS aparece inactivo en todo el cluster o solo en uno.
- Revisar si hay tareas de backup, importaciones o plantillas que dependan de ese storage.
- Evitar operaciones que puedan escribir ahí hasta tener claro el estado.
- Mirar el NAS o el camino de red antes de tocar más la config de Proxmox.
A veces la tentación es desmontar, volver a montar y confiar en que el problema desaparezca. Yo prefiero no empezar por ahí cuando el remoto directamente no responde. Remontar un recurso que cuelga porque el host está caído no arregla la red. Solo te da la sensación agradable de haber hecho algo.
lo que no hago ya nunca#
no doy por válido un CIFS porque siga en mount#
Esto me parece la lección más útil. El montaje visible no equivale a salud.
no dejo que un job crítico use un storage remoto sin validación real#
Si el script solo comprueba que el directorio existe, el problema no es el storage. El problema es el script.
no convierto un share de red en cajón de sastre#
Cuantos más usos mezclas, más difícil es priorizar cuando falla.
no me precipito a culpar a Proxmox#
Proxmox te está contando lo que ve. Si el host remoto está muerto, el drama probablemente vive fuera del nodo.
dónde encaja esto con el resto de mi forma de llevar el homelab#
Este tipo de fallo se entiende mejor si miras el homelab como un sistema y no como una colección de servicios sueltos. Si el storage ya venía raro, entonces cualquier operación que dependa de él cambia de riesgo. Eso enlaza bastante con la rutina que conté en Cómo reviso la salud de un cluster Proxmox en dos minutos antes de tocar nada. También conecta con pvesm status en Proxmox: cómo leo el almacenamiento de verdad y qué señales no ignoro, porque una línea inactive no es el final de la historia. A veces justo ahí empieza la parte útil.
Y si además trabajas con montajes de red para backups o archivos auxiliares, yo me quedaría también con la obsesión sana de validar de verdad cada destino. NFS, CIFS, lo que toque. El nombre del protocolo cambia menos de lo que parece. Lo importante es no fiarte de una comprobación vaga.
mi conclusión#
Cuando un storage CIFS en Proxmox parece seguir montado pero responde Host is down al tocarlo, yo lo leo como una advertencia bastante clara. El nodo conserva el montaje, sí, pero la conectividad real con el servidor remoto ya no está garantizada. Y para operar eso significa que el storage no es usable, aunque la foto superficial sugiera otra cosa.
Lo que me llevo de esta madrugada es muy simple. En recursos de red, ver no es lo mismo que poder usar. Si mount dice una cosa y df dice otra, yo me quedo con la segunda. Porque es la que te obliga a hablar con el remoto de verdad.
Puede sonar desconfiado. Lo es. Y en homelab esa desconfianza me ha ahorrado más de una tontería.
referencias#
- Storage CIFS en Proxmox VE
- Storage en Proxmox VE
- Post relacionado: Backups por NFS en homelab: cómo valido el montaje antes de llenar el disco local
- Post relacionado: pvesm status en Proxmox: cómo leo el almacenamiento de verdad y qué señales no ignoro
- Post relacionado: Cómo reviso la salud de un cluster Proxmox en dos minutos antes de tocar nada