No me preocupa actualizar Proxmox. Lo que me preocupa es hacerlo con esa falsa tranquilidad de quien ve cuatro checks verdes y piensa que ya está todo bajo control. En un nodo suelto ya hay margen para liarla. En un cluster pequeño, todavía más. No porque Proxmox sea frágil, sino porque en casa solemos mezclar infra razonable con decisiones que tomamos medio dormidos.
Mi experiencia con esto es bastante simple. Los upgrades salen bien cuando llegas con contexto. Se tuercen cuando entras con prisa, ejecutas apt full-upgrade porque hoy te viene bien y solo después descubres que había un paquete raro, un nodo con quorum justo o una VM donde no tocaba.
Esta madrugada volví a hacer el mismo preflight que sigo siempre antes de actualizar un host Proxmox. No es un runbook académico. Es una rutina corta, práctica y bastante desconfiada. A mí me sirve justo para eso, para decidir si hoy toca actualizar o si hoy toca cerrar la pestaña y no ponerse creativo.
por qué nunca arranco por apt full-upgrade#
Hay una tentación muy humana en homelab. Ves paquetes pendientes, recuerdas que llevas días diciendo que luego actualizas y te dices que son cinco minutos. Luego resulta que entre esos paquetes está corosync, hay kernels acumulados, uno de los nodos tiene una carga menos obvia de la que recordabas y el rato de mantenimiento deja de ser pequeño.
Lo que aprendí es que el problema rara vez es el comando. El problema es el momento en que lo lanzas.
Por eso mi regla es sencilla. Antes de actualizar, primero quiero saber tres cosas.
- cómo está realmente el nodo
- cómo está realmente el cluster
- qué impacto tendría un reinicio si el upgrade lo pide
Si no tengo esas tres respuestas, no sigo.
1. pveversion -v me dice si el nodo viene limpio o ya trae historias raras#
Lo primero que miro es pveversion -v. La interfaz web me sirve para ver la versión general, pero para preflight prefiero la salida completa. Ahí veo el pve-manager, el kernel en uso, los kernels antiguos que siguen instalados y, sobre todo, si hay algo que ya huele mal antes de tocar nada.
Esta es una captura saneada de una comprobación real.
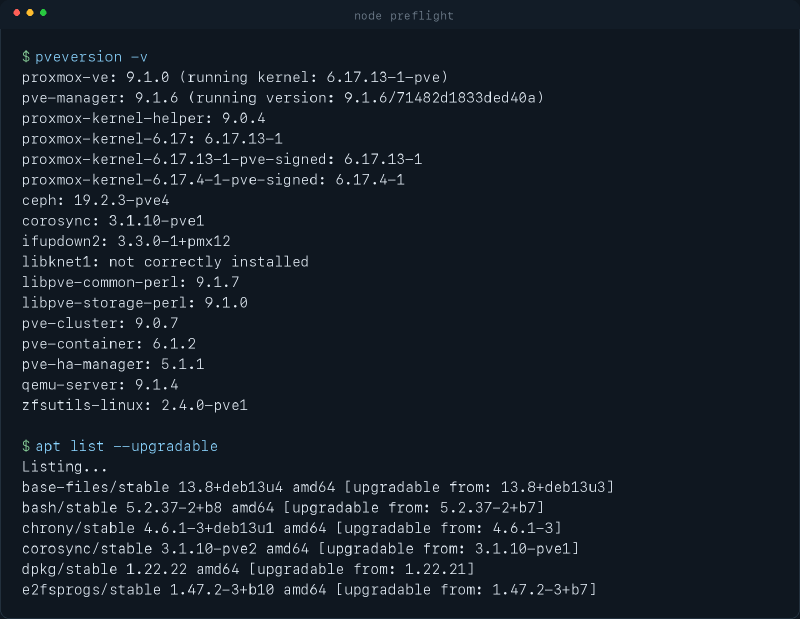
Aquí hay varias cosas que me interesan.
La primera es la obvia. Quiero ver qué versión corre de verdad el nodo. No solo Proxmox VE, también el kernel activo. Si el nodo está en una combinación rara o en un salto que no tenía previsto, ya cambia mi lectura del upgrade.
La segunda es menos vistosa pero más útil. Quiero detectar líneas raras. En esta revisión apareció un libknet1: not correctly installed. Eso no significa automáticamente desastre, pero sí significa “para un segundo y no trates esto como una actualización rutinaria”. Esa clase de detalle es justo la que me hace gracia revisar antes y no a mitad del proceso.
También miro si se han quedado varios kernels antiguos. No porque sea una tragedia, sino porque me da contexto sobre cuántas vueltas llevo posponiendo limpieza y mantenimiento real. Cuando un nodo acumula demasiado pasado, conviene no actuar como si fuera una máquina recién salida del horno.
Mi opinión aquí es bastante clara. Si pveversion -v ya cuenta una historia rara, no me interesa ser valiente. Me interesa entender la rareza primero.
2. apt list --upgradable no lo miro por cantidad, lo miro por tipo de paquete#
Después miro qué hay pendiente con apt list --upgradable. No me importa tanto si son ocho paquetes o treinta. Lo que me importa es qué piezas toca esa tanda.
No es lo mismo actualizar utilidades sueltas que ver en la lista cosas como corosync, paquetes base de Debian, cronía del sistema o componentes que afectan directamente a cluster y almacenamiento.
En la captura de arriba se ve justo eso. Había actualización pendiente de corosync, chrony, varias librerías base y utilidades nucleares. Eso me cambia el tono del trabajo. No porque actualizarlo sea mala idea, al contrario. Pero si entran piezas así en la ecuación, entonces ya no trato el upgrade como un gesto mecánico.
Cuando veo algo relacionado con cluster, hora o red, subo el nivel de prudencia. La razón es muy simple. Muchas incidencias feas en Proxmox no nacen de una gran avería, nacen de una combinación mediocre entre mantenimiento correcto y contexto insuficiente.
También me ayuda a responder una pregunta práctica. ¿Este nodo puede actualizarse ya o conviene reservar una ventana un poco más limpia? Si el lote viene cargado y además sé que ese host sostiene cosas que prefiero no mover con prisa, me espero.
3. si el cluster no está sano, no actualizo ningún nodo por deporte#
Lo siguiente para mí es obligatorio. pvecm status.
No negocio esta parte. Puedes tener el nodo precioso, con paquetes claros y una lista de upgrades perfectamente razonable. Si el cluster no está sano, no me pongo a tocar nada serio.
Esta salida también sale de una comprobación real y la he saneado para no enseñar direcciones internas.
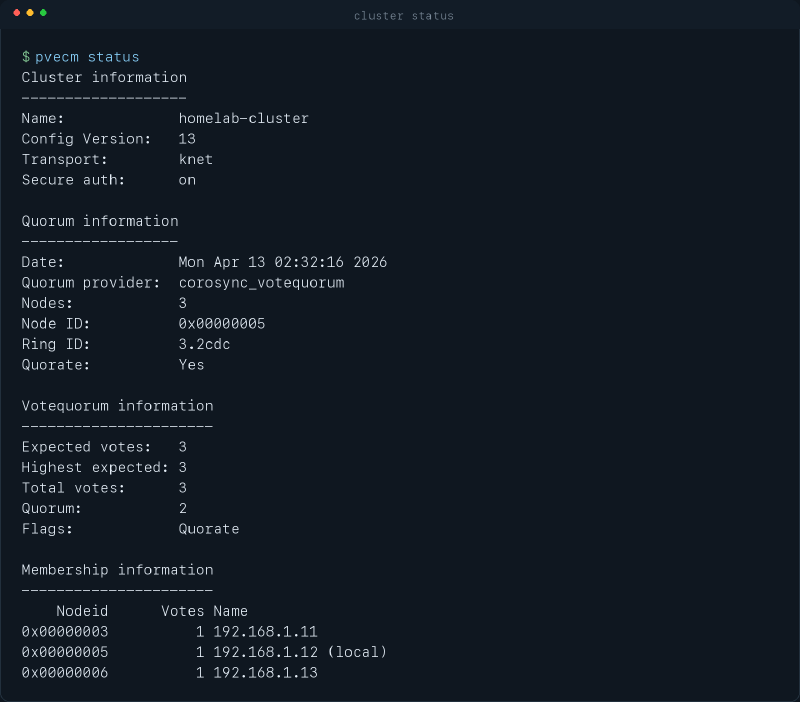
Aquí busco una historia muy concreta.
Quiero ver Quorate: Yes. Quiero ver tres votos esperados y tres votos presentes. Quiero ver los nodos que espero ver. Y quiero que esa foto llegue limpia, sin sensación de que el cluster hoy está bien “más o menos”.
El “más o menos” no me vale para actualizar.
Esto enlaza bastante con lo que conté en Cómo reviso la salud de un cluster Proxmox en dos minutos antes de tocar nada. Allí el foco era una revisión general. Aquí el contexto es todavía más concreto. Si voy a tocar paquetes que pueden pedir reinicio, necesito que quorum y membresía estén impecables antes de empezar.
Además, Proxmox no lo oculta. En la guía oficial de upgrade insiste en varias cosas que me parecen bastante sensatas. Cluster sano, backup probado, acceso fiable al nodo y espacio libre decente. Parece obvio hasta que te pilla una noche en la que ibas “solo a actualizar rápido”.
4. después miro HA porque un cluster sano no siempre es un cluster cómodo de tocar#
Con quorum limpio, paso a ha-manager status.
Esto no es manía, es contexto. Un cluster puede estar perfectamente quorate y aun así no ser buen momento para tocar un nodo si los servicios HA relevantes están donde no te viene bien o si hay algo parado que no recuerdas haber parado tú.
Yo quiero ver qué recurso está en qué nodo, quién es el master activo y si hay servicios que me obliguen a migrar o a replantearme el orden. En un homelab pequeño, donde la distribución de cargas no siempre sigue una lógica industrial, esta revisión me ahorra bastante tontería.
Y aquí entra un matiz importante. HA no es una excusa para actuar sin pensar. Mucha gente cae en la idea de que, como hay alta disponibilidad, ya puedes tocar un nodo a lo bruto. Yo no lo compro. HA reduce dolor, pero no sustituye el juicio. Si una VM crítica vive justo donde vas a actualizar y además hay otro nodo ya bastante ocupado, prefiero preparar el terreno antes de dejar que la teoría haga magia.
5. qm list y pct list me dicen si ese nodo está realmente disponible para mantenimiento#
Antes de tocar paquetes también paso por el inventario local. qm list y pct list.
Esto merece post propio, de hecho lo tendrá esta misma tanda, porque me parece de las comprobaciones más infravaloradas que hay en Proxmox. No me sirve saber que el cluster está bien si luego descubro tarde que ese nodo concreto carga más cosas de las que recordaba.
Quiero ver qué VMs siguen vivas ahí, qué contenedores están arrancados y si hay algo que convenga mover o apagar con orden antes de que un posible reinicio lo decida por mí. A veces la foto que tienes en la cabeza va con varios días de retraso. El comando no.
Esa diferencia es la que evita upgrades torpes.
6. si no tengo backup probado, no me cuento cuentos#
Aquí tengo una opinión poco glamourosa. La frase “tengo backup” no significa gran cosa si no sabes si restaura. En homelab nos gusta mucho hablar de copias y menos de pruebas de restauración. Hasta que una actualización sale regular y entonces descubrimos que el backup existía, sí, pero como concepto filosófico.
Yo no necesito montar un simulacro completo cada vez que voy a actualizar un nodo. Pero sí quiero saber que las copias recientes existen, que el destino está bien y que no dependen de un storage de red medio roto. Después de ver fallos con montajes NFS o CIFS que parecen vivos y no lo están, me fío bastante menos de los supuestos.
Si vienes de leer Backups por NFS en homelab: cómo valido el montaje antes de llenar el disco local o Storage CIFS en Proxmox: cuando parece montado pero te responde “Host is down”, ya sabes por dónde voy. Un path existe o un storage aparece configurado no significa que tu red de seguridad sea real.
7. espacio libre y acceso al nodo, dos cosas aburridas que se vuelven muy interesantes cuando algo falla#
La documentación oficial recomienda tener al menos 5 GB libres en raíz, mejor más de 10. Estoy bastante de acuerdo. No porque Proxmox sea especialmente tragón en un upgrade normal, sino porque el margen corto siempre te pilla en el peor momento.
También intento no depender de una única vía de acceso. Si tengo consola o acceso fuera de banda, mejor. Si solo hay SSH, uso tmux o similar. Parece exagerado hasta que la sesión se corta y te acuerdas de golpe de por qué esa recomendación lleva años repitiéndose en toda guía seria.
En casa no siempre tenemos IPMI bonito ni consola empresarial. Precisamente por eso me gusta preparar mejor el nodo antes de tocarlo. Cuando la vía de rescate es mediocre, tu tolerancia al riesgo también debería bajar.
8. la secuencia que sigo yo antes de actualizar#
Mi preflight real suele ser así.
pveversion -vapt list --upgradablepvecm statusha-manager statusqm listypct list- revisión rápida de backups y storage implicado
- confirmar espacio libre y acceso fiable
No siempre me lleva el mismo tiempo. Si todo viene limpio, en pocos minutos tengo una decisión. Si aparece una anomalía, entonces el objetivo ya no es actualizar. El objetivo es entender esa anomalía.
Eso para mí es la parte importante. El preflight no existe para hacerte sentir profesional. Existe para darte permiso a no seguir si la foto no es buena.
qué me hace parar en seco#
Hay algunas señales que para mí significan “hoy no”.
un paquete raro o mal instalado#
Si pveversion -v ya canta algo que no debería, no lo empujo debajo de la alfombra. Prefiero arreglar eso antes.
quorum dudoso o nodo ausente#
Si el cluster no está completamente sano, no actualizo un miembro por inercia. Me da igual que técnicamente quizá pudiera salir bien.
recursos HA en una situación que no entiendo#
Si un servicio está donde no esperaba o hay estados que no me cuadran, me obligo a entender la historia antes.
carga real más alta de la que recordaba#
Si ese nodo lleva más VMs o contenedores importantes de los que pensaba, cambio el plan. Migrar antes suele ser más barato que improvisar después.
dudas razonables sobre backup o storage#
Si la red de seguridad depende de un destino que no he validado, no doy el salto con alegría.
lo que me ha enseñado este hábito#
La lección menos sexy de todas es que actualizar bien se parece mucho a no tener prisa. La mayoría de sustos que he visto en homelab no venían de una complejidad técnica brutal. Venían de juntar mantenimiento correcto con un momento absurdo.
Proxmox suele ser bastante noble cuando lo tratas con un poco de respeto. El problema aparece cuando interpretamos esa nobleza como permiso para ir a ciegas. Y no, no es lo mismo.
Para mí el preflight cumple justo esa función. Me obliga a mirar el nodo como sistema operativo, como miembro de cluster y como anfitrión de cargas reales. Hasta que no encajan esas tres capas, no paso al siguiente paso.
mi conclusión#
Antes de un apt full-upgrade en Proxmox yo no quiero solo una lista de paquetes. Quiero una historia coherente. La versión del nodo tiene que cuadrar, la lista de upgrades tiene que tener sentido, el cluster tiene que estar sano, HA tiene que estar tranquilo y las cargas del host tienen que ser compatibles con mantenimiento.
Si todo eso encaja, actualizo con bastante paz. Si no encaja, no me hago el héroe.
Y la verdad es que esta forma de trabajar me ha ahorrado más tiempo del que consume. Cinco minutos de chequeo serio salen muchísimo más baratos que una hora de arqueología digital después de un reinicio inoportuno.
referencias#
- Guía oficial de upgrade de Proxmox VE 8 a 9
- Cluster Manager en Proxmox VE
- High Availability en Proxmox VE
- Post relacionado: Cómo reviso la salud de un cluster Proxmox en dos minutos antes de tocar nada
- Post relacionado: Storage CIFS en Proxmox: cuando parece montado pero te responde “Host is down”
- Post relacionado: Backups por NFS en homelab: cómo valido el montaje antes de llenar el disco local