Imagínate que Richard Hendricks de Silicon Valley aparece con su algoritmo de compresión y lo aplica al KV cache de los LLMs. Más o menos eso es lo que acaba de presentar Google Research en ICLR 2026. Se llama TurboQuant y, si corre en tu hardware, es básicamente un upgrade gratuito.
El problema que nadie te había contado bien # Cuando ejecutas un modelo de lenguaje grande —ya sea un Llama 3.3 70B o un Qwen 2.5 32B en tu homelab— el cuello de botella no es lo que imaginas. No es la velocidad de procesamiento del transformer, ni los pesos del modelo. Es el KV cache.
Este no es un post de teoría sobre IA. Es lo que realmente tengo montado, lo que ha funcionado, lo que no, y por qué creo que la forma en que muchas empresas están aproximándose a los agentes de IA está mal planteada.
Contexto: gestiono la distribución de varias marcas de cosmética de lujo en España. Marcas con catálogos grandes (cientos de productos), terminología muy específica (ingredientes activos, protocolos de tratamiento, formaciones de terapeuta), y materiales que constantemente hay que adaptar: manuales, fichas de producto, presentaciones para clientes, contenido para redes sociales.
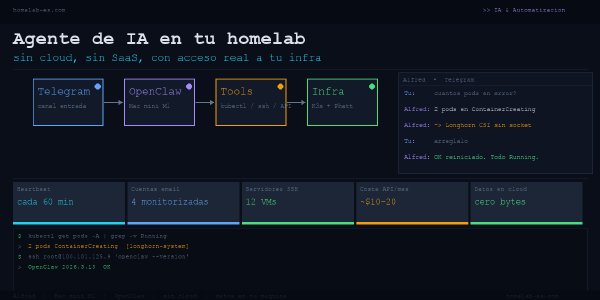
Un agente de IA que monitoriza tu infraestructura, revisa el email y ejecuta comandos en tu clúster K3s. Sin SaaS, sin datos que salen de tu red. Esto es lo que monté y lo que aprendí tras meses usándolo.
En el post sobre Ollama expliqué cómo montar modelos de lenguaje en local. Lo que no conté es que usar Ollama directamente por terminal tiene sus limitaciones. Funciona, pero no es cómodo para el uso diario.
Open WebUI resuelve eso. Es una interfaz web para Ollama que se parece mucho a ChatGPT en apariencia y funcionalidad, pero corre en tu propia red, sin enviar datos a nadie, y sin límites de uso.