Hay una clase de fallo que me parece bastante peor que un error claro. El fallo silencioso. El que no rompe con estruendo, no manda una alarma espectacular y no te deja un log rojo diciendo “esto ha salido mal”. Solo sigue adelante, aparenta normalidad y mientras tanto te está preparando una hostia para más tarde.
Eso fue exactamente lo que me obsesionó con mis backups por NFS. El problema no era que el backup remoto se cayera. Eso puede pasar. El problema era algo más traicionero. El montaje remoto no estaba donde debía, el script aún tenía un camino alternativo local, y la combinación de ambas cosas podía convertir una copia supuestamente segura en un proceso bastante eficiente llenando el disco del host.
Hay una fase bastante cutre en casi todo homelab con Proxmox. La de decirte a ti mismo que levantar una VM nueva son cinco minutos y luego echar media hora repitiendo siempre lo mismo. Crear la máquina, montar ISO o importar imagen, tocar red, meter clave SSH, actualizar paquetes, instalar cuatro utilidades, corregir alguna tontería del hostname y cruzar los dedos para no haber dejado un usuario raro o una configuración vieja de otra prueba. No es un drama, pero tampoco es serio.
Hay una cosa que me sigue haciendo gracia del mundo self-hosted. Montamos infra cada vez más compleja para acabar resolviendo tareas que, en el fondo, se arreglan con dos comandos bien puestos y un poco de criterio. Publicar una web estática es una de ellas.
He probado flujos más elaborados. CI/CD con más capas, builders remotos, pipelines con demasiadas piezas, deploys muy listos sobre el papel y algo menos listos cuando fallan a las dos de la mañana. Al final he vuelto a lo que mejor me funciona para proyectos pequeños y medianos que controlo yo: Hugo para generar el sitio y rsync para dejarlo en el servidor.
Tengo un servidor de Gitea funcionando desde hace tiempo. Lo usé durante años para alojar código personal, scripts del homelab, y configuraciones. Cuando apareció Forgejo como fork de Gitea, al principio lo ignoré. Otro fork más. Luego fui leyendo más sobre el tema y terminé migrando.
La historia es la siguiente: en 2022, los mantenedores principales de Gitea crearon una empresa, Gitea Ltd., que asumió el control del proyecto y de la marca. Parte de la comunidad de contribuidores lo vio como un cambio de gobernanza problemático, crearon un fork llamado Forgejo bajo la Software Freedom Conservancy para mantener el proyecto gobernado por la comunidad de forma transparente. El código inicial es el mismo, pero los caminos están divergiendo.
Durante mucho tiempo usé Telegram para las notificaciones del homelab. Tenía un bot que me mandaba mensajes cuando terminaba un backup, cuando se caía un servicio, o cuando algún script de automatización fallaba. Funcionaba bien, pero dependía de la API de Telegram, necesitaba mantener el token del bot, y ocasionalmente Telegram tenía algún problema de conectividad que retrasaba las alertas.
Descubrí Ntfy buscando una alternativa y me quedé con él en dos días. La idea es tan simple que al principio no me lo creía: un servidor HTTP que actúa de broker de mensajes. Publicas en un topic con un POST, y cualquier cliente suscrito a ese topic recibe la notificación. Sin cuentas, sin OAuth, sin configuración compleja.
Tuve una historia de amor y odio con los backups durante años. Amor porque siempre tenía la intención de montarlo bien. Odio porque cada solución que intentaba tenía algo que me echaba atrás: demasiado complicada, demasiado lenta, imposible de verificar, o que dejaba de funcionar en silencio durante semanas sin que yo me enterara.
Rsync para hacer copias de directorios. Duplicati con su interfaz web que prometía mucho y entregaba poco. Borg Backup, que es técnicamente excelente pero que tiene una curva de aprendizaje suficientemente pronunciada como para que lo dejara a medias dos veces.
Empecé con Zapier como todo el mundo. Luego pasé a Make (antes Integromat) cuando los precios de Zapier me parecieron excesivos para lo que usaba. Y finalmente llegué a n8n, lo monté en mi homelab, y desde entonces no he vuelto a pagar por ningún servicio de automatización cloud.
Esto no es una comparativa superficial. Llevo más de un año con n8n en producción, tengo más de 40 workflows activos, y he migrado casi todo lo que antes hacía en Make. Te cuento lo que funciona, lo que no, y cómo montarlo sin complicarte la vida.
Llevo años peleándome con scrapers que fallan en la mitad de las webs. Curl y wget para páginas estáticas, Playwright para las que necesitan JavaScript, Selenium para las que son especialmente cabronas… y siempre el mismo problema: login. Si la página necesita que estés autenticado, la cosa se complica bastante.
La semana pasada instalé browser-use CLI y cambió bastante el panorama. No es magia, pero es la herramienta más práctica que he encontrado para automatizar el navegador desde la terminal de una forma sencilla y que además puede usar tus sesiones reales de Chrome. Sin configurar credenciales. Sin gestionar cookies manualmente.
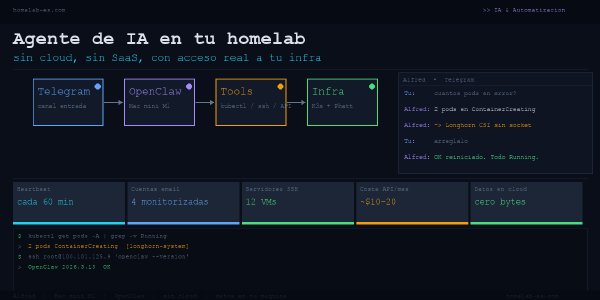
Un agente de IA que monitoriza tu infraestructura, revisa el email y ejecuta comandos en tu clúster K3s. Sin SaaS, sin datos que salen de tu red. Esto es lo que monté y lo que aprendí tras meses usándolo.
Cuando tienes un servidor, SSH y un script de Bash funcionan bien. Cuando tienes tres, copiar y pegar comandos todavía es manejable. Cuando llegas a cinco o más, necesitas Ansible.
Yo descubrí Ansible cuando mi homelab pasó de 2 a 8 nodos. Mantener actualizados los sistemas, desplegar configuraciones, instalar paquetes, todo eso manualmente se volvió insostenible. Un día actualicé 7 servidores pero olvidé el octavo. Obvio, ese fue el que falló en producción días después.